In this blog post, we will be discussing Pandas’ dropna method. This method is used for dropping rows and columns that have missing values. Pandas is a powerful data analysis library for Python, and the dropna function is one of its most useful features. As data scientists, it is important to be able to handle missing data, and Pandas’ dropna function makes this easy.
Pandas dropna Method
Pandas’ dropna function allows us to drop rows or columns with missing values in our dataframe. Find the documentation of Pandas dropna method on this page: pandas.DataFrame.dropna. The dropna method looks like the following:
DataFrame.dropna(axis=0, how=’any’, thresh=None, subset=None, inplace=False)
Given the above method and parameters, the following are some common scenarios in which dropna method can be used:
- Drop rows having one or more missing values: The value of ‘axis’ parameter is set as 0
- Drop columns having one or more missing values: The value of axis is set as 1
- Drop rows where all columns have missing values: The value of ‘how’ parameter is set as ‘all’
- Drop rows that have fewer than n real values: The value of ‘thresh’ parameter is set to n real values
- Drop rows where one or more missing values in any specific columns: The value of ‘subset’ parameter is passed the column names in array form []
Python Code Examples of Pandas dropna Method
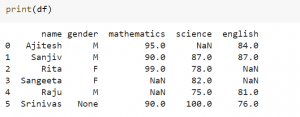
Here is the Python code for some of the dropna scenarios that we discussed above. Before getting into the examples, lets create a dataframe which can be used for working with dropna method. The code below represents different way in which Pandas dataframe can be created.
import pandas as pd
df = pd.DataFrame([['Ajitesh', 'M', 95,None, 84],
['Sanjiv', 'M', 90,87,87],
['Rita', 'F',99,78,None],
['Sangeeta', 'F',None,82,None],
['Raju','M',None,75,81],
['Srinivas',None,90,100,76]])
df.columns = ['name', 'gender', 'mathematics', 'science', 'english']
#Another way to form above dataframe is the following:
data = {'name':['Ajitesh', 'Sanjiv', 'Rita', 'Sangeeta', 'Raju', 'Srinivas'],
'gender':['M','M','F','F','M',None],
'mathematics':[95, 90, 99,None,None,90],
'science':[None,87,78,82,75, 100],
'english':[84, 87, None, None, 81, 76]}
df2 = pd.DataFrame(data)
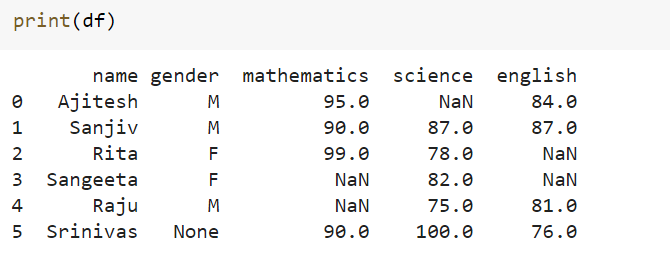
Now that the above dataframe is created, lets look at different scenarios listed in the previous section.
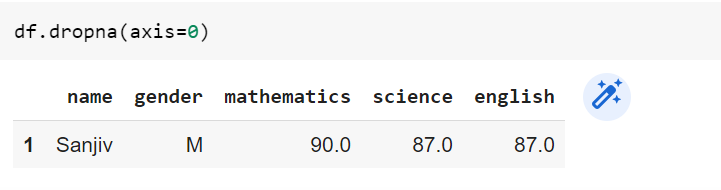
Drop rows that contain missing values: Note that the value of axis is set to 0
df.dropna(axis=0)
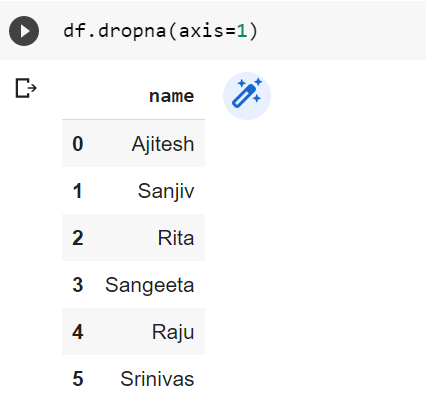
Drop columns that contain missing values: Note that the value of axis is set to 1
df.dropna(axis=1)
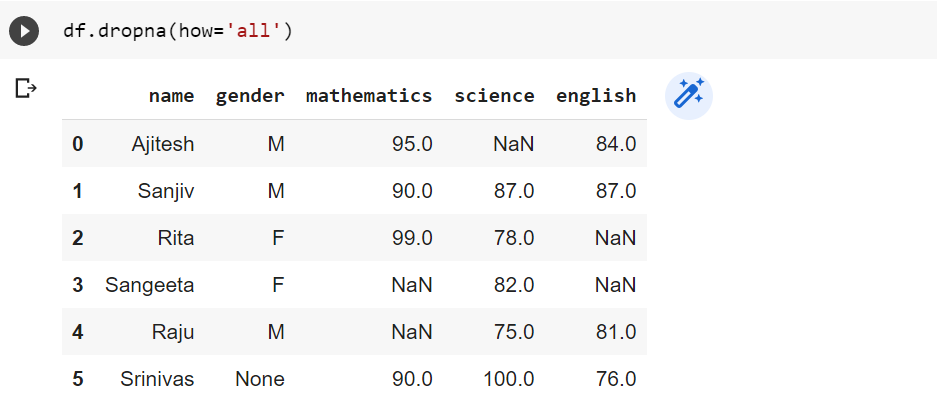
Drop rows where all columns have missing values: Note that the value of how attribute is set to ‘all’. The default value of ‘how’ attribute is ‘any’.
df.dropna(how='all')
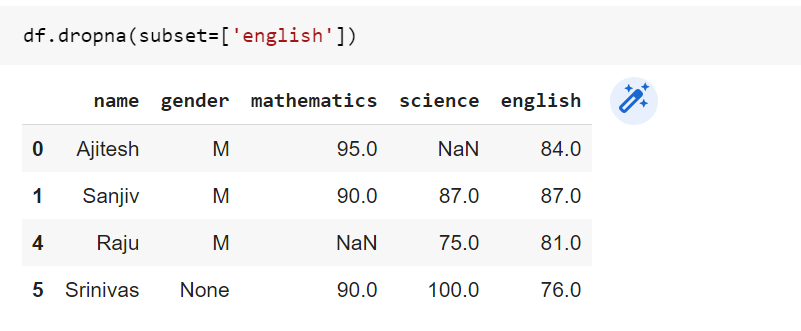
Drop rows where one or more missing values in any specific columns: Note that the value of subset is set to ‘english’ which means that remove all the rows which has NaN value in ‘english’ column.
df.dropna(subset=['english'])
Drop rows that have fewer than n real values: Note that setting the value of threshold (thresh) to 4 removes the column with label ‘Sangeeta’ as this is row having fewer than 4 real values.
df.dropna(thresh=4)


Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me