Have you come across the problem of handling missing data/values for respective features in machine learning (ML) models during prediction time? This is different from handling missing data for features during training/testing phase of ML models. Data scientists are expected to come up with an appropriate strategy to handle missing data during, both, model training/testing phase and also model prediction time (runtime). In this post, you will learn about some of the following imputation techniques which could be used to replace missing data with appropriate values during model prediction time.
- Validate input data before feeding into ML model; Discard data instances with missing values
- Predicted value imputation
- Distribution-based imputation
- Unique value imputation
- Reduced feature models
Below is the diagram representing the missing data imputation techniques during runtime (model prediction time).
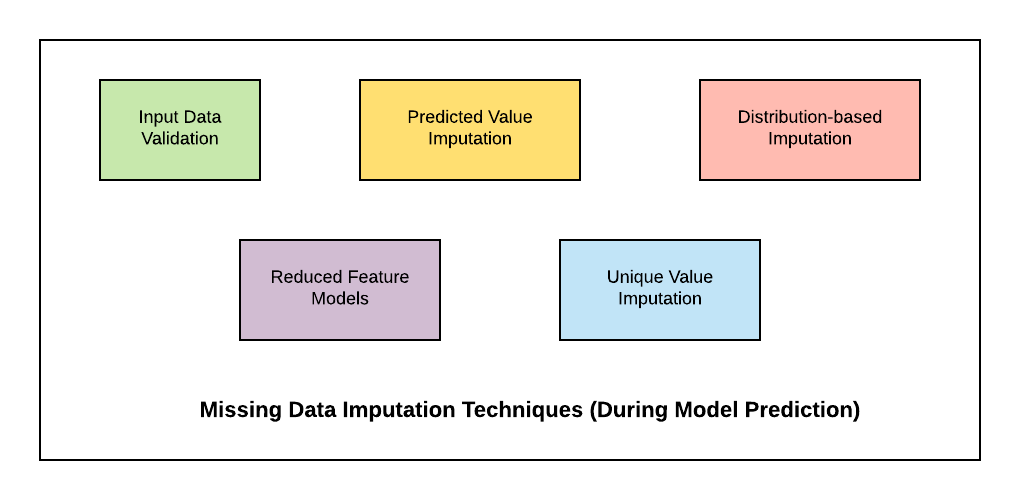
Fig. Missing Data Imputation Techniques
Lets quickly understand what is Imputation?
Imputation is the process of replacing missing data with substituted values. In this post, different techniques have been discussed for imputing data with an appropriate value at the time of making a prediction. When imputed data is substituted for a data point, it is known as unit imputation; when it is substituted for a component of a data point, it is known as item imputation. At the time of model training/testing phase, missing data if not imputed with proper technique could lead to model bias which tends to degrade model performance.
Input Data Validation – Discard Data Instance with Missing Data
Most trivial of all the missing data imputation techniques is discarding the data instances which do not have values present for all the features. In other words, before sending the data to the model, the consumer/caller program validates if data for all the features are present. If the data for all of the features are not present, the caller program do not invoke the model at all and takes on some value or show exceptions. For beginners, this could be a technique to start with. If this technique is used during training model training/testing phase, it could result in model bias.
Predicted Value Imputation (PVI)
In this technique, one of the following methods is followed to impute missing data and invoke the model appropriately to get the predictions:
- Impute with mean, median or mode value: In place of missing value, mean, median or mode value is taken appropriately for continuous and categorical data respectively. Recall that the mean, median and mode are the central tendency measures of any given data set. The goal is to find out which is a better measure of central tendency of data and use that value for replacing missing values appropriately. You can check the details including Python code in this post – Replace missing values with mean, median & mode. Here is the thumb rule:
- When to use mean: If the data is symmetrically distributed, one can make use of mean for replacing missing value. One can use box plot or distribution plot to find out about the data distribution.
- When to use median: If the data is skewed or if the data consists of outliers, one may want to use median.
- When to use mode: If the data is skewed, one may want to use mode.
- Impute with predicted value: Another technique is understanding/learning the relationship between missing data and other features value in other test instances where data were found for feature representing missing data, and appropriately predict the missing data based on the value of other features for the instances where data is found to be missing. One could, however, argue that if a feature value can be estimated using other feature values, isn’t it the case of correlates and thus the feature could be imputed. One needs to watch out for feature imputability scenarios.
Distribution-based Imputation (DBI)
In this technique, for the (estimated) distribution over the values of an attribute/feature (for which data is missing), one may estimate the expected distribution of the target variable (weighting the possible assignments of the missing values). The final prediction could be weighted average (mean or mode) value of all the prediction. This strategy is common for applying classification trees in AI research and practice. This technique is fundamentally different from predicted value imputation because it combines the classifications across the distribution of a feature’s possible values, rather than merely making the classification based on its most likely value.
Unique Value Imputation
In this technique, a unique value is imputed in place of missing values. This technique is recommended when it can be determined if the data is generally found to be missing for a particular label/class value and, this dependence is found during model training/testing phase. One of the techniques used for imputing missing data with unique value is randomly selecting the similar records. This is also termed as hot deck cold deck imputation technique. The random selection for missing data imputation could be instances such as selection of last observation (also termed Last observation carried forward – LOCF).
Reduced Feature Models
In this technique, different models are built with the different set of features with the idea that appropriate models with only those set of features are used for making predictions for which the data is available. This is against applying imputation to missing data using one of the above techniques. For example, let’s say that a model is built with feature A, B, AB, C, D. As part of analysis it is found out that most of the time, data related to feature D would be missing. Thus, using the reduced feature modeling technique, another model using features A, B, AB, and C is built. In production, both the models get deployed and in case the data is found to be missing data for feature D, the model trained with features A, B, AB and C is used or else, the model with all features including feature D is used.
Which Technique is Superior? Reduced Feature Models, PVI, DBI
It has been experimentally found that reduced feature modeling is a superior technique from performance perspective out of all the other techniques mentioned above. However, reduced feature modeling is an expensive one at the same time from different perspectives such as resource intensive, maintenance etc.
References
Summary
In this post, you learned about different techniques which could be used for imputing missing data with appropriate value during prediction time. Note that this is different techniques used for handling missing data imputation during model training phase. The most important missing data imputation techniques for handling missing data during prediction time are reduced feature models, distribution-based imputation, prediction value imputation.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me