As data scientists and MLOps Engineers, you must have come across the challenges related to managing GPU requirements for training and deploying large language models (LLMs). In this blog, we will delve deep into the intricacies of GPU memory demands when dealing with LLMs. We’ll learn with the help of various examples to better understand how GPU memory impacts the performance and feasibility of training these LLMs. Whether you’re planning to train a foundation (pre-trained) model or fine-tuning an existing model, the insights are aimed to guide you through the crucial considerations of GPU memory allocation. Greater details can be found in this book: Generative AI on AWS.
Understanding GPU Memory Requirements for LLMs
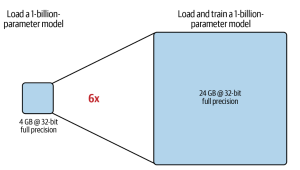
Let’s start with understanding how much GPU memory will be needed to load and load/train a 1 billion parameter LLM. A single-model parameter, at full 32-bit precision, is represented by 4 bytes. Therefore, a 1-billion-parameter model requires 4 GB of GPU RAM just to load the model into GPU RAM at full precision. To train the model, you will need much more than 4GB GPU RAM as for each parameter (4 bytes) we will need memory for storing related optimizer states, gradients, activations, and temp memory. This would require an additional 12-20 bytes per model parameter. Thus, overall, it would need 16-24 bytes per model parameter. That would mean that it would require anywhere between 16 GB to 24 GB of GPU memory to load and train a 1-billion parameter LLM.
In summary, it can be said that while it would require around 4GB of GPU memory to load the 1 billion parameter LLM, it would require around 16-24 GB of GPU memory to train this model.
How do we train 100B+ LLM given GPU Memory Limitation?
Given the above, the question arises as to how we train an LLM of 100+ Billion parameters, as we have seen how there is a need for 16-24 GB of GPU memory for loading and training a 1-billion parameter LLM. NVIDIA A100, currently, has a limit of 80GB RAM support. This is where the concept of quantization comes into the picture. The idea is to convert the LLM model parameters from 32-bit precision down to 16-bit precision or even 8-bit or 4-bit. By reducing the precision from 32 to 16 bits, the GPU memory requirement can be cut down to half. That means from 24 GB, we will need 12 GB GPU memory for training 1-billion parameter of 16-bit precision.
Quantization reduces the memory needed to load and train a model by reducing the precision of the model weights. The following represents how GPU memory requirements are reduced for loading LLMs, based on quantization.
| Model Type | Precision | GPU RAM Requirements |
|---|---|---|
| Full-precision model | 32-bit full | 4 GB |
| 16-bit quantized model | 16-bit half | 2 GB |
| 8-bit quantized model | 8-bit | 1 GB |
The idea is to adopt quantization if you try to load and train a very large LLM while leveraging the current available GPU support such as NVIDIA A100 (80G). For larger models, you will likely need to use a distributed cluster of GPUs to train these massive models across hundreds or thousands of GPUs based on distributed computing patterns, including distributed data-parallel (DDP) and fully sharded data parallel (FSDP). DDP is recommended if model parameters can fit into a single GPU (with or without quantization). One copy of the model is loaded into each GPU. Otherwise, FSDP is recommended to shard the model across multiple GPUs.
Example: GPU Requirements & Cost for training 7B Llama 2
As per the post – 7B Llama 2 model costs about $760,000 to pretrain – by Dr. Sebastian Raschka, it took a total number of 184,320 GPU hours to train this model. The following is the math:
- The total number of GPU hours needed is 184,320 hours.
- The cost of running one A100 instance per hour is approximately $33.
- Each instance has 8 A100 GPUs. That’s 184320 / 8 * 33 ~ $760,000

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

Hello!
Thank you for your article on LLM training and GPU memory requirements. It was very helpful. After reading it, I have a question!
When considering memory requirements for inferencing, as opposed to training, are there different factors to consider?
When assessing memory needs for inferencing with Large Language Models (LLMs), factors diverge from training requirements. Key considerations include model size, batch size for processing requests, and optimization techniques like quantization, pruning and distillation that reduce memory footprint. Unlike the extensive resources needed for training, inferencing focuses on efficient execution within constrained environments, emphasizing speed and memory efficiency to accommodate real-time applications and potentially limited hardware capabilities.