This article represents key steps of Hadoop Map-Reduce Jobs using a word count example. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos.
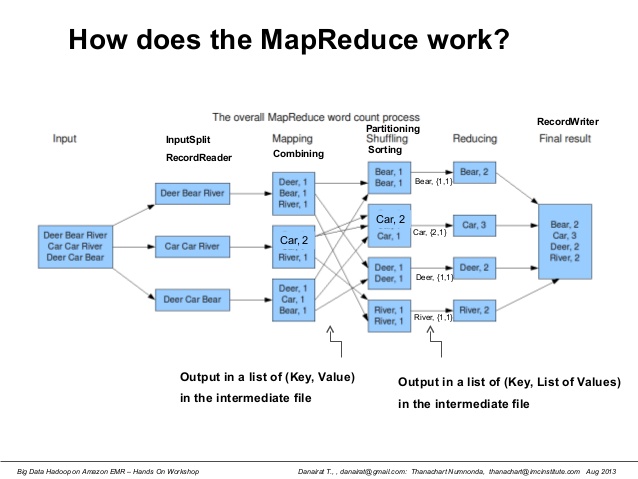
Following are the key steps of how Hadoop MapReduce works in a word count problem:
- Input is fed to a program, say a RecordReader, that reads data line-by-line or record-by-record.
- Mapping process starts which includes following steps:
- Combining: Combines the data (word) with its count such as 1
- Partitioning: Creates one partition for each word occurence
- Shuffling: Move words to right partition
- Sorting: Sort the partition by word
- Last step is Reducing which comes up with the result such as word count for each occurence of word.
Following diagram represents above steps.
Following diagram depicts another view on how map-reduce works:
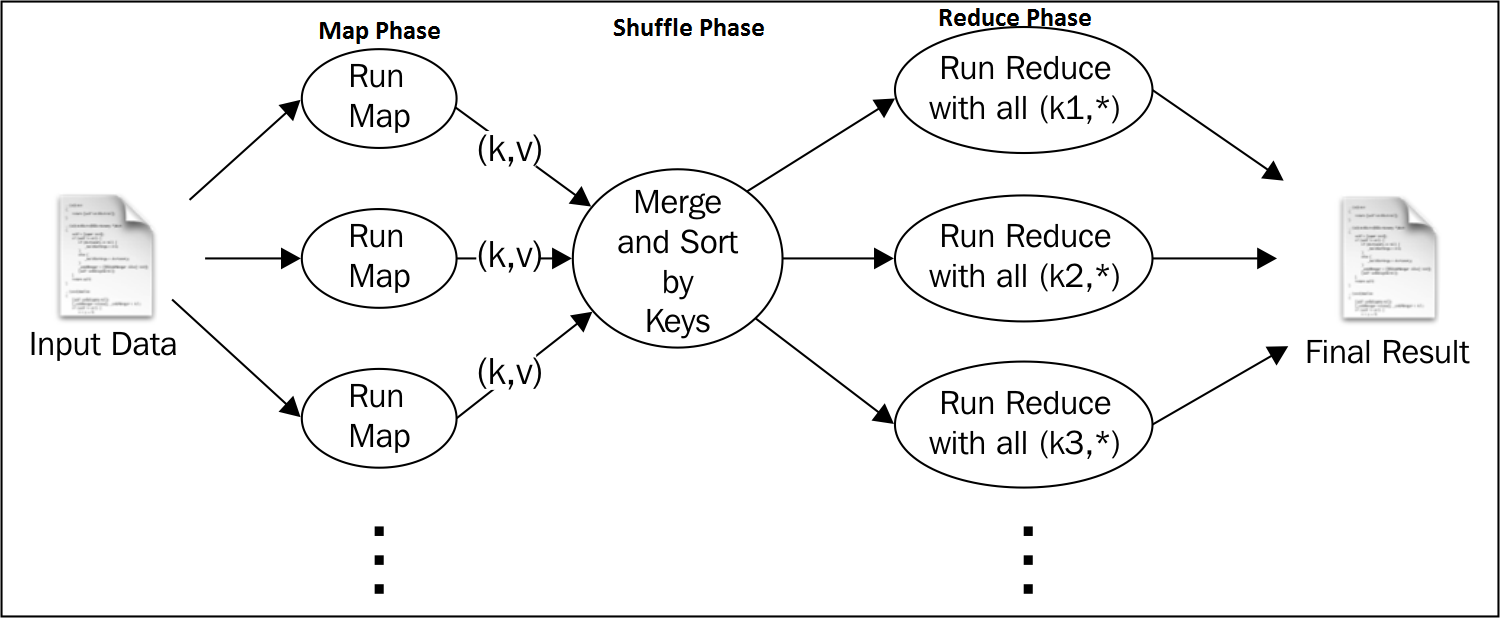
In above diagram, one could see that, primarily, there are three key phases of a map-reduce job:
- Map: This phase processes data in form of key-value pairs
- Partitioning/Shuffling/Sorting: This groups similar keys together and sort them
- Reduce: This places final result with the key.

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning and BI. I would love to connect with you on Linkedin.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Latest posts by Ajitesh Kumar (see all)
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me