How can machines accurately classify text into categories? What enables them to recognize specific entities like names, locations, or dates within a sea of words? How is it possible for a computer to comprehend and respond to complex human questions? These remarkable capabilities are now a reality, thanks to encoder-only transformer architectures like BERT. From text classification and Named Entity Recognition (NER) to question answering and more, these models have revolutionized the way we interact with and process language.
In the realm of AI and machine learning, encoder-only transformer models like BERT, DistilBERT, RoBERTa, and others have emerged as game-changing innovations. These models not only facilitate a deeper understanding of language but also drive a wide array of applications related to text classification, question answering, etc. In this blog pos, we will explore various types of encoder-only transformer models, delve into their unique features, and discover real-world applications. Whether you’re a data scientist, AI enthusiast, or just curious about how different types of encoder-only transformer models works, this blog will help you get up to speed.
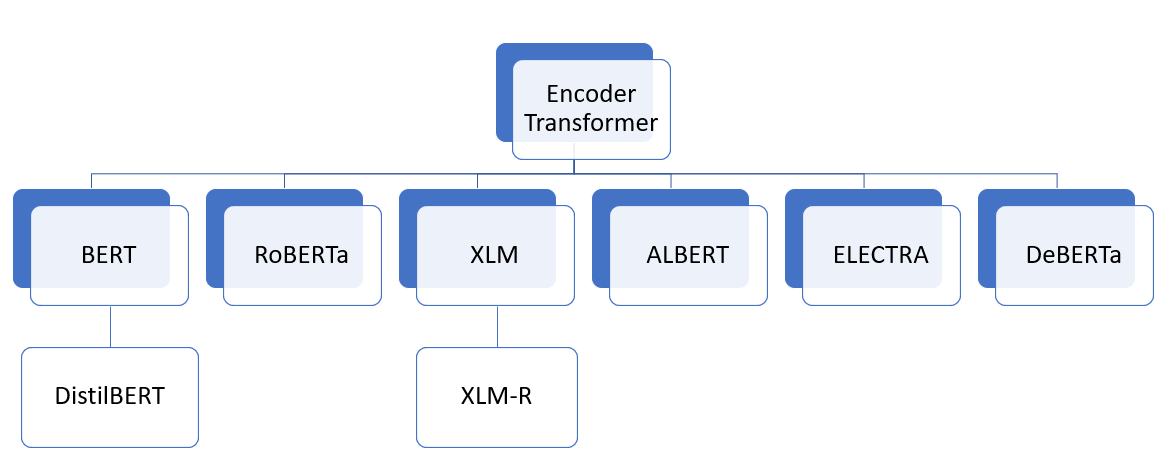
Let’s dive into the details of each of these encoder-only transformer models, which are revolutionizing the field of Natural Language Processing (NLP). We’ll look at the unique features, architecture, and applications of each model in the following picture:
BERT (Bidirectional Encoder Representations from Transformers)
BERT is one of the most prominent pre-trained transformer models developed by Google. It’s bidirectional, meaning it processes words concerning all the other words in a sentence, rather than one by one in order. The following are some of the unique features of BERT model:
- Bidirectional Training: Understands the context of a word based on its surroundings.
- Pre-training Tasks: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP).
- Multiple Layers: Commonly available in 12 (BERT Base) and 24 (BERT Large) layers.
Encoder only models such as BERT is popular choice for natural language understanding (NLU) tasks such as text classification (sentiment analysis, etc), named entity recognition (NER) and question answering.
DistilBERT
DistilBERT is a distilled version of BERT developed by Hugging Face. It retains most of BERT’s performance but is lighter, faster, and smaller. It uses 40% fewer parameters than BERT and 60% faster while achieving ~95% of BERT performance. It uses a technique called knowledge distillation during pre-training. Knowledge distillation is the process of transferring the knowledge from a large, sophisticated model (often referred to as the “teacher” model) to a smaller, simpler model (known as the “student” model). DistilBERT is designed as a student model with 40% fewer parameters.
RoBERTa
RoBERTa is a variant of BERT with improved pretraining techniques and hyperparameters. It goes through a longer training with larger batches and more data. It removed the NSP task to focus solely on MLM, thus, resulting in better performance than original BERT model.
XLM (Cross Lingual Model)
XLM aims to provide solutions for cross-lingual tasks. It is trained with different pre-training objectives including autoregressive language modeling from GPT-like models and MLM from BERT. It also got another pre-training objective namely translation language modeling (TLM) which can be understood as an extension to MLM for multiple language inputs. In TLM, the model is trained on parallel sentences in different languages, with some tokens masked, promoting cross-lingual understanding. For example, Input (English-French): “The weather is [MASK] – Le temps est [MASK]”. XLM achieved top performance in benchmarks such as XNLI, a cross-lingual natural language inference dataset.
XLM-R (RoBERTa)
XLM-RoBERTa (XLM-R) is a combination of XLM and RoBERTa which is focused on cross-lingual understanding while upscaling with a very large volume of dataset (RoBERTa). It inherited features from both XLM and RoBERTa. An encoder with MLM was trained on massively large corpus of 2.5TB of text taken from common crawl corpus. The TLM pre-training objective of XLM was dropped as there was no parallel text in the corpus. This model can be used in global businesses to analyze customer feedback in various languages.
ALBERT (A Lite BERT)
ALBERT builds upon the foundational concepts of BERT while introducing novel methods to reduce the model’s size and increase efficiency. The primary objective is to create a lighter and more efficient version of BERT without significant loss of performance. It does it by achieving a reduction in the number of parameters while making it more memory-efficient. The following are three key changes made to BERT architecture:
- Smaller embedding dimension: The embedding dimension is split from the hidden dimension which reduces the size of embedding dimension thereby reducing parameters.
- Parameter sharing across the layers: Unlike BERT, which has unique parameters for each layer, ALBERT shares parameters across all layers, significantly reducing the model size.
- Sentence order prediction (SOP): Unlike BERT’s Next Sentence Prediction (NSP), ALBERT introduces SOP, which is more challenging and helps the model learn inter-sentence coherence. NSP objective is replaced.
ALBERT is used in scenarios where memory optimization is crucial without sacrificing performance, such as cloud-based NLP services.
ELECTRA
ELECTRA model overcomes a limitation in the standard Masked Language Modeling (MLM) pretraining objective used by models like BERT. In standard MLM pre-training approach, only the representations of the masked tokens are updated during training, leaving the other tokens untouched. A substantial amount of information in the unmasked tokens goes unused, making the training less efficient. For example, if the input is “The weather is [MASK] today”, only the masked token (e.g., “sunny”) is focused on, and the representations of other tokens (“The”, “weather”, “is”, “today”) are not updated.
ELECTRA follows two model approach.
- The first model works like a standard masked language model thereby predicting masked tokens. This model is often designed to be smaller and less resource-intensive.
- The second model works like a discriminator that predicts which tokens in the generator’s output were originally masked. It makes a binary decision for every token, leading to much more efficient training. If the input is The weather is cloudy today, the prediction is “False, False, False, True, False” (indicating that only “cloudy” was masked).
For specific tasks like text classification, sentiment analysis, etc., only the discriminator part is fine-tuned. The fine-tuning process resembles that of a standard BERT model.
DeBERTa
DeBERTa (Decoding-enhanced BERT with disentangled attention) is a transformer model that introduces novel techniques to enhance the understanding of context and relationships within the text. DeBERTa’s architecture builds on the transformer design, with specific modifications and enhancements that differentiate it from other models like BERT.
Traditional attention mixes content and position information, potentially leading to less precise understanding. DeBERTa disentangles content and position in the attention scores. Each token is represented by two vectors, one for the content and other for the position. This helped model the dependency of nearby tokens in a better manner in self-attention layers.
Conclusion
The models we discussed included BERT, DistilBERT, RoBERTa, XLM, XLM-RoBERTa, ALBERT, DeBERTa, and ELECTRA, each bringing unique features and advancements that cater to different needs and applications. From BERT’s bidirectional understanding to DistilBERT’s efficiency through knowledge distillation, from RoBERTa’s optimized training to XLM’s cross-lingual capabilities, these models are reshaping how machines understand and generate human language. ALBERT’s parameter sharing has opened doors to memory optimization, while DeBERTa’s disentangled attention offers nuanced understanding. ELECTRA, with its replaced token detection, has set a new standard for efficiency. Real-world examples, such as search query understanding, chatbots, content recommendation, legal document analysis, and more, demonstrate the tangible impact these models are having across industries.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me