This post intends to propose a technique termed as Dual Coding for testing or performing quality control checks on machine learning models from quality assurance (QA) perspective. This could be useful in performing black box testing of ML models.
The proposed technique is based on the principles of Dual Coding Theory (DCT) hypothesized by Allan Paivio of the University of Western Ontario in 1971. According to Dual Coding Theory, our brain uses two different systems including verbal and non-verbal/visual to the gather, process, store and retrieve (recall) the information related to a particular subject. One of the key assumptions of dual coding theory is the connections (also termed as referential connections) that link verbal and nonverbal representations into a complex associative network. For example, let’s say we are shown flower images and also told about the name of these flowers (such as rose, lotus etc). At a later point in time, when told about one of these flowers by name, or shown one of the images, we end up classifying them as flowers. Pay attention to the fact of one of the two systems (verbal or non-verbal/visual) get activated appropriately to classify the subject (word or images) in the correct manner. The following diagram represents different representations of a dual-coding theory.
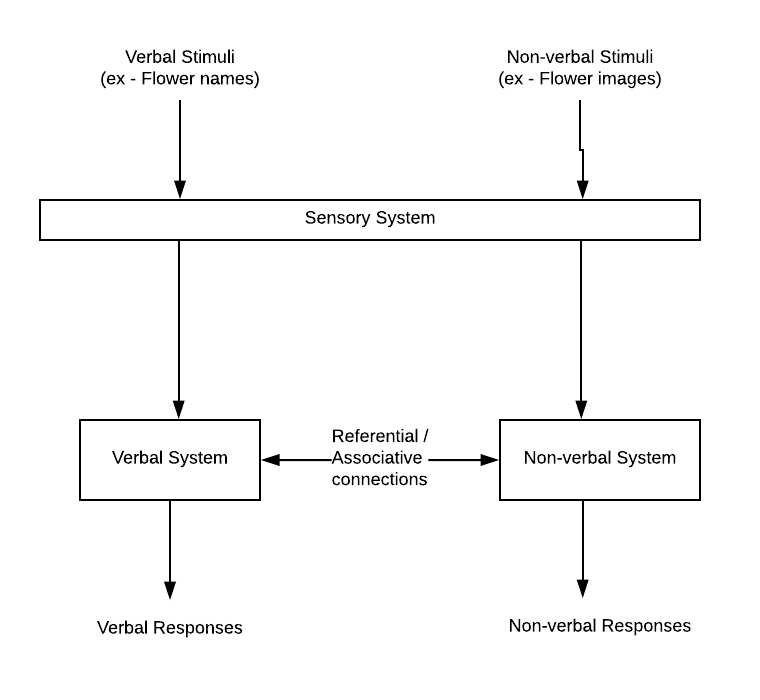
Fig 1. Dual Coding Theory
This very idea is proposed to be used for testing the prediction of machine learning models for its correctness. Models are built (trained and tested) using different algorithms by making use of the same or similar/common set of features. Later, at the time of testing the predictions, two or more models are fed with the same input data and their predictions are compared for correctness. The details are described in one of the later sections.
The idea behind dual coding testing is to test the quality of the program by testing two different implementations of the same program (one being the main program) for a given set of inputs and comparing their outputs for correctness.
In this post, you will learn some of the following topics:
- Dual coding testing technique for machine learning models
- Why dual coding testing for machine learning models
- Automation of dual coding testing of ML models
- Skills needed for dual coding testing
Dual Coding Testing for Machine Learning Models
Applying the dual coding theory to machine learning, it would mean testing the models created using two different algorithms while using the same or most common set of features. Let’s try and understand this using an example.
Let’s say, a classification model needs to be built for predicting whether a person is suffering from a disease or not. As a general practice, the model gets built using different algorithms (such as random forest, SVM, logistic regression etc) with a common set of features. Based on the model’s performance, one of the models is chosen as the final model (random forest) to be moved into production. In order to test the correctness of the prediction of a model (chosen as the final one to be deployed – random forest), one could compare the prediction output of the model with that of alternate models built using different algorithms (such as SVM, logistic regressions mentioned earlier in this example). The diagram below represents the testing technique based on principles of dual coding theory:
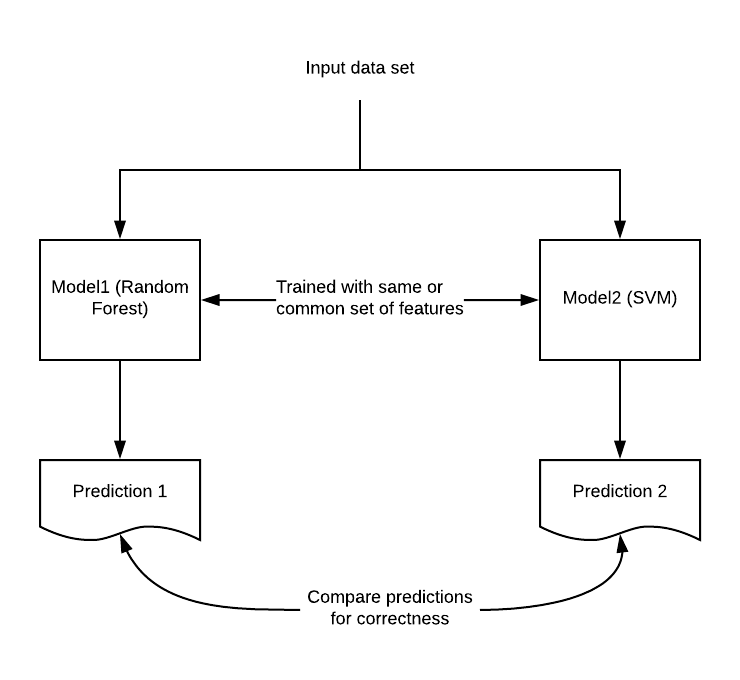
Fig 2. Testing Machine Learning Models – Dual Coding Principles
In case, there are predictions from the main model which differs from those made from alternate models, one could raise the defects in the bug tracking system for further analysis by the data scientists.
Why Dual Coding Testing for Machine Learning Models
Machine learning models have been termed as “non-testable” due to the absence of test oracle.
Briefly speaking, a test oracle is an external mechanism such as test engineers or testing programs which are used to test the correctness of a program by comparing the output of the program with the expected value. The absence of test oracle would mean one of the following:
- Either the test engineers to verify the correctness could not be found or test programs could not be written
- It is very difficult to test the program given the complexity associated with the testing.
In the case of machine learning models, the expected value is not known beforehand as they are used to make the predictions. Thus, it would be very difficult to write the test program or find test engineers which/who could verify the correctness of the model’s output (prediction) with that of expected value (which is not known beforehand). Find greater details with examples on this post, why machine learning systems are non-testable.
Automation of Dual Coding Testing of ML models
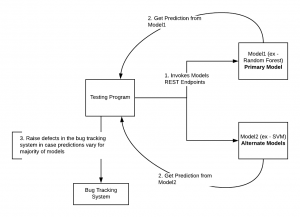
Given that dual coding testing is about testing the output (prediction) of a model by comparing the outputs with that of outputs from other models created using different algorithms, this could be automated in the following manner:
- Models created using different algorithms are deployed in testing environments.
- Models are exposed as REST endpoints.
- A testing program/script could invoke models using REST protocol.
- Testing program invokes two or more models with a given set of inputs
- The testing program compares the predictions (output) and raises the defect in bug tracking based on some policies.
The diagram below represents the above automation:
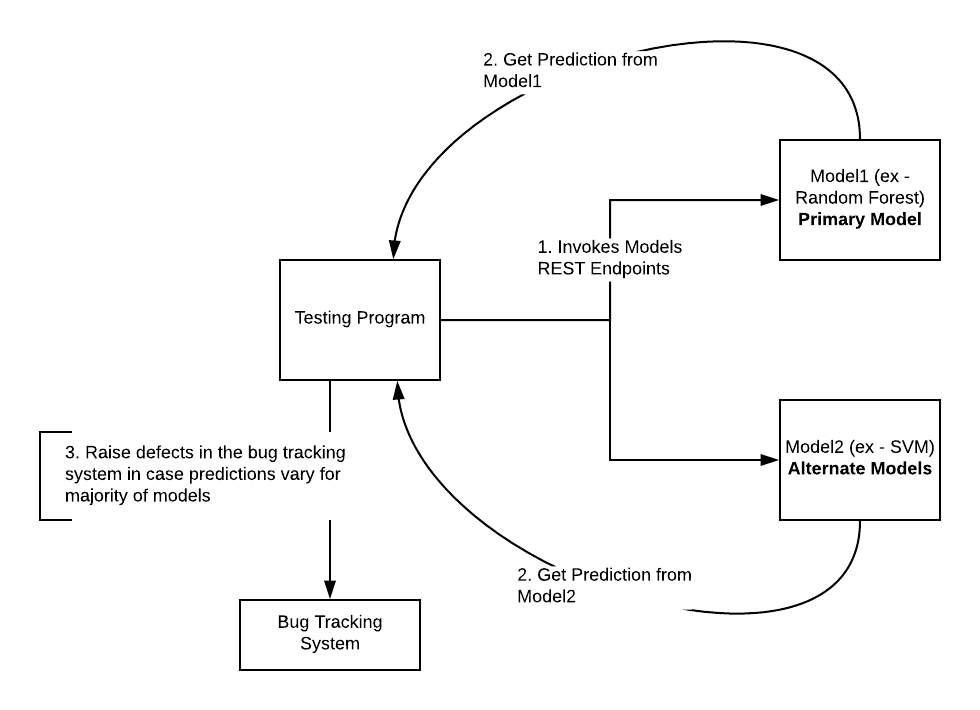
Fig 3. Automation of Dual Coding Testing of ML Models
Skills for Dual Coding Testing of ML Models
The following represents some of the skills required for conducting dual coding tests or writing automation tests:
- Machine learning algorithms knowledge to interpret the outputs from different models
- Experience with one or more programming or scripting language to write test programs which integrates with models REST endpoints
- Knowledge of REST protocol
References
- Machine learning
- Dual coding theory and education
- Classifying pictures and words: Implications for the dual-coding hypothesis
Summary
In this post, you learned about applying dual coding principles hypothesized by Paivio for testing the correctness of predictions made by machine learning models. The primary idea taken from the dual coding theory is that human brains maintain two different mental representations including verbal and non-verbal (visual) systems to learn (get trained) about a particular topic. And, later, it uses the learning to classify the subject appropriately. Similarly, two or models built using different algorithms and same or common set of features could be tested for their prediction correctness by comparing their results.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me