Last updated: 11 Aug, 2024
When working with machine learning models, data scientists often come across a fundamental question: What sets parametric and non-parametric models apart? What are the key differences between these two different classes of models? What needs to be done when working on these models? This is also one of the most frequent questions asked in the interviews.
Machine learning models can be parametric or non-parametric. Parametric models are those that require the specification of some parameters before they can be used to make predictions, while non-parametric models do not rely on any specific parameter settings and therefore often produce more accurate results. These two distinct approaches play a crucial role in predictive modeling, each offering unique advantages and considerations. This blog post discusses parametric vs non-parametric machine learning models with examples along with the key differences.
What are parametric and non-parametric models?
Parametric models require fitting data into a mathematical equation which is a function of a set of parameters that define the underlying distribution of the data. This predetermined structure allows parametric models to make predictions based on a fixed number of parameters, regardless of the size of the training dataset. Common examples of parametric models include linear regression, Lasso regression, Ridge regression, logistic regression, support vector machine, neural network etc. Linear regression is a parametric learning algorithm, which means that its purpose is to examine a dataset and find the optimum values for parameters in an equation
When working with parametric models, one is required to fit the data to a mathematical function having different parameters. When estimating the function (called function approximation), the following two steps are followed:
- Identifying the function: The first step is to identify the function such as linear or non-linear function.
- Identifying the parameters of the function.
The training or fitting of the parametric models boils down to estimating the parameters. Here is an example of the parametric model also called as linear regression model having different parameters (coefficients).
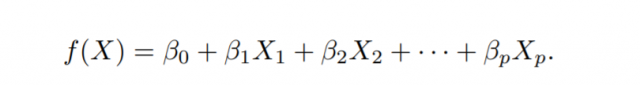
Such models are called parametric models. The parametric models can be linear models which include determining the parameters such as that shown above. The most common approach to fitting the above model is referred to as the ordinary least squares (OLS) method. However, least squares are one of many possible ways to fit the linear model.
Building non-parametric models does not make explicit assumptions about the functional form such as a linear model in the case of parametric models. Instead, non-parametric models can be seen as the function approximation that gets as close to the data points as possible. Non-parametric models do not rely on predefined parameter settings, enabling them to adapt to complex and irregular patterns within the data. The advantage over parametric approaches is that by avoiding the assumption of a particular functional form such as a linear model, non-parametric models have the potential to accurately fit a wider range of possible shapes for the actual function. Any parametric approach brings with it the possibility that the functional form (linear model) which is very different from the true function, in which case the resulting model will not fit the data well. Examples of non-parametric models include fully non-linear algorithms such as k-nearest neighbors, bagging, boosting, support vector machines, decision trees, random forests, etc.
What’s the difference between parametric and non-parametric models?
The following is the list of differences between parametric and non-parametric machine learning models.
- In the case of parametric models, the assumption related to the functional form is made and a linear model is considered. In the case of non-parametric models, the assumption about the functional form is not made.
- Parametric models are much easier to fit than non-parametric models because parametric machine learning models only require the estimation of a set of parameters as the model is identified before a linear model. In the case of a non-parametric model, one needs to estimate some arbitrary function which is a much more difficult task.
- Parametric models often do not match the unknown function we are trying to estimate. The model performance is comparatively lower than the non-parametric models. The estimates done by the parametric models will be farther from being true.
- Parametric models are interpretable, unlike non-parametric models. This essentially means that one can go for parametric models when the goal is to find an inference. Instead, one can choose to go for non-parametric models when the goal is to make predictions with higher accuracy and interpretability or inference is not the key ask.
Here are the differences in the tabular form:
| Parametric Models | Non-Parametric Models | |
|---|---|---|
| Definition | Require predefined parameter settings | Do not rely on specific parameters |
| Flexibility | Less flexible, assume fixed data structure | Highly flexible, adapt to complex patterns |
| Assumptions | Make strong assumptions about data distribution | Fewer assumptions about data distribution |
| Complexity | Simpler model structure | More complex model structure |
| Interpretability | More interpretable | Less interpretable |
| Performance | Efficient for large datasets with limited features | Perform well with high-dimensional data |
When to use parametric vs non-parametric algorithms/methods for building machine learning models?
When the goal is to achieve models with high-performance prediction accuracy, one can go for non-linear methods such as bagging, boosting, support vector machines bagging boosting with non-linear kernels, and neural networks (deep learning). When the goal is to achieve modeling for making inferences, one can go for parametric methods such as lasso regression, linear regression, etc which have high interpretability. You may want to check a related post on the difference between prediction and inference – Machine learning: Prediction & Inference Difference
Why does it matter whether a learning algorithm is parametric or nonparametric?
Because datasets used to train parametric models frequently need to be normalized. At its simplest, normalizing data means making sure all the values in all the columns have consistent ranges. Training parametric models with unnormalized data—for example, a dataset that contains values from 0 to 1 in one column and 0 to 1,000,000 in another—can make those models less accurate or prevent them from converging on a solution altogether. This is particularly true with support vector machines and neural networks, but it applies to other parametric models as well.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
Nice piece. Thanks a lot. I enjoyed every bit of this blog.
This is very descriptive and comprehensive article about parametric and non-parametric models. Thanks a lot.
It is a great reading to understand the difference between parametric and nonparametric models with examples.