
Have you ever wondered how AI can create lifelike images that are virtually indistinguishable from reality? Well, there is a neural network architecture, Deep Convolutional Generative Adversarial Network (DCGAN) that has revolutionized image generation, from medical imaging to video game design. DCGAN’s ability to create high-resolution, visually stunning images has brought it into great usage across numerous real-world applications. From enhancing data augmentation in medical imaging to inspiring artists with novel artworks, DCGAN‘s impact transcends traditional machine learning boundaries.
In this blog, we will delve into the fundamental concepts behind the DCGAN architecture, exploring its key components and the ingenious interplay between its generator and discriminator networks. Together, these components work in an adversarial manner to produce authentic images that seem to defy reality.
What’s DCGAN? What are its key components?
DCGAN stands for Deep Convolutional Generative Adversarial Network. It is a type of generative model introduced by Alec Radford, Luke Metz, Soumith Chintala in 2015 in this paper, Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. DCGANs are an extension of the original GAN architecture and are specifically designed for image generation tasks.
In DCGAN, the generator and discriminator networks are both based on convolutional neural networks (CNNs), making it well-suited for processing images. The generator takes random noise as input and learns to generate realistic images, while the discriminator learns to distinguish between real images from the dataset and fake images produced by the generator. During training, the generator and discriminator are trained in an adversarial manner, with the ultimate goal of the generator producing images that are indistinguishable from real images. Let’s look at each of these components in detail.
Generator Network
The generator network takes random noise as input and learns to generate realistic images from that noise. Its primary task is to map points from a latent space (usually a random vector) to the data space (the image space). The generator typically consists of a series of convolutional layers, followed by batch normalization and ReLU activation functions. It may also use transposed convolutions (also known as deconvolutions or upsampling layers) to upscale the feature maps, allowing the generation of higher-resolution images.
The main steps in the generator architecture are as follows:
- Input: A random noise vector or latent space vector.
- Convolutional Layers: These layers take the input noise vector and upsample it to generate feature maps with increasing spatial dimensions and decreasing depth.
- Batch Normalization: It normalizes the activations in each layer, helping to stabilize the training process.
- ReLU Activation: Rectified Linear Unit (ReLU) activation function is used after each batch normalization layer to introduce non-linearity.
- Output Layer: The final layer usually employs a tanh activation function to squash the pixel values between -1 and 1, generating the final synthetic image.
Discriminator Network
The discriminator network is responsible for distinguishing between real images from the training dataset and fake images produced by the generator. It takes an image as input and learns to classify it as real (1) or fake (0). Like the generator, the discriminator also consists of a series of convolutional layers, batch normalization, and activation functions.
The main steps in the discriminator architecture are as follows:
- Input: An image (either real or generated).
- Convolutional Layers: These layers process the input image and downsample it to produce feature maps with reduced spatial dimensions and increased depth.
- Batch Normalization: Similar to the generator, batch normalization is used to stabilize training.
- Leaky ReLU Activation: Unlike standard ReLU, Leaky ReLU allows small negative values, preventing issues like the “dying ReLU” problem.
- Output Layer: The output layer is a single neuron with a sigmoid activation function, producing a probability score (between 0 and 1) indicating whether the input image is real or fake.
How is DCGAN trained?
In the training process of a Deep Convolutional Generative Adversarial Network (DCGAN), we focus on two crucial components: the generator and the discriminator.
In the training process of the discriminator, a training set is composed, consisting of a combination of real images from the dataset and fake images generated by the generator. This step is treated as a supervised learning problem, where labels of 1 are assigned to real images and 0 to fake images. The loss function utilized for this process is binary cross-entropy.
In the training process of the generator, the objective is to score each generated image with an aim to optimize towards higher scores. This is achieved with the help of the discriminator network. By passing a batch of generated images through the discriminator network, the scores for each image is retrieved. The loss function of the generator network is defined as the binary cross-entropy between these probabilities and a vector of ones. The aim is to train the generator to produce images that the discriminator perceives as real.
The following picture represents the training process of DCGAN
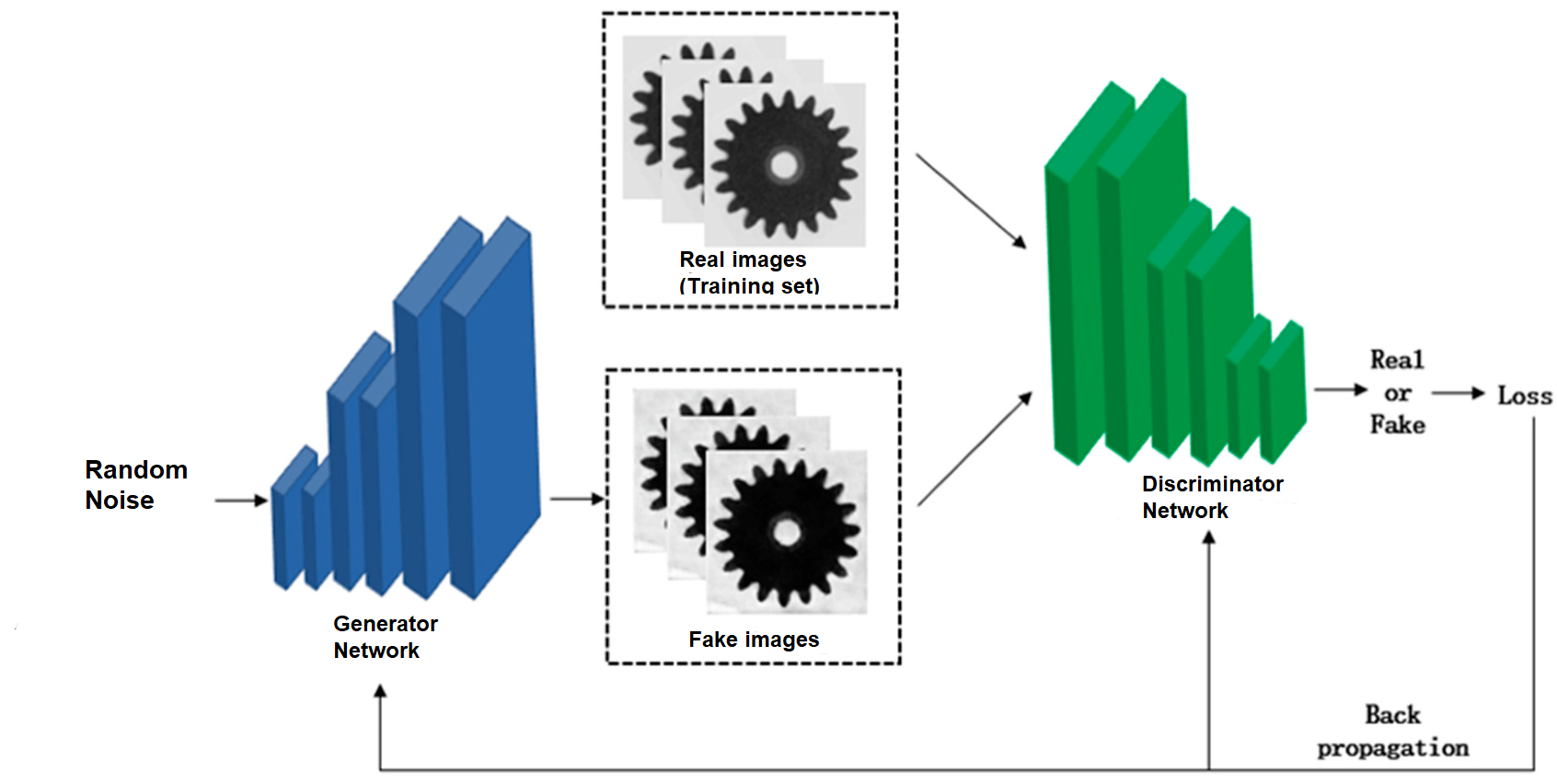
A critical aspect contributing to the success of DCGAN is the meticulous alternation of training between the generator and discriminator. Throughout the training process, the weights of only one network are updated at any given time, while the other remains fixed. For instance, during the generator training phase, only the generator’s weights are updated. This deliberate separation serves to prevent the discriminator from merely adapting to predict generated images as real, which could hinder the generator’s progress. Instead, the objective is to have the generator produce images that the discerning discriminator perceives as authentic and genuine.
Real-life Examples of DCGAN Applications
The following are some of the applications in different domains where DCGAN has found interesting and useful applications:
- Image Synthesis: DCGANs have been used to generate realistic images of objects, faces, animals, and scenes. These synthetic images can be valuable for data augmentation and training machine learning models in situations where collecting real data is challenging.
- Art and Design: DCGANs have been utilized by artists and designers to create unique and visually captivating artworks, logos, and graphics.
- Video Game Design: DCGANs have been used to generate realistic textures, landscapes, and characters for video games, reducing the need for manual asset creation.
- Deep fakes: DCGAN has found applications in the creation and manipulation of deep fakes, a term used to describe manipulated media content, typically involving images or videos that are synthetically altered to depict events or scenarios that never occurred. While deep fakes can have both positive and negative implications, DCGAN’s image generation capabilities have been leveraged in creating realistic and convincing deep fakes.
- Lesion Detection and Segmentation: DCGAN can be used in conjunction with other segmentation techniques to detect and segment lesions or abnormalities in medical images. The generated images can contribute to the creation of robust models for computer-assisted diagnostics.
- Image Super-Resolution: DCGAN can upscale medical images to higher resolutions, which is particularly valuable in medical imaging techniques such as MRI or CT scans. The improved resolution can lead to more accurate diagnoses and aid in identifying subtle anomalies.
- Data Augmentation: DCGAN can be used for data augmentation, which involves generating diverse variations of existing images including medical images / scans. Augmented datasets can improve the generalization and robustness of machine learning models, enabling more accurate diagnoses and treatment predictions.
Conclusion
DCGAN’s simple yet powerful architecture, with convolutional layers and adversarial training, enables the generation of high-quality, realistic images. Its stability and ability to handle varying input sizes make it ideal for image-related tasks. DCGAN has found applications in diverse fields, including art generation, video game design, medical imaging, etc. Its capacity for data augmentation, image-to-image translation, and super-resolution has transformed how we approach these domains. While DCGAN opens new possibilities, it also brings ethical challenges, particularly concerning deep fakes and privacy. Responsible use and ethical awareness are essential in ensuring the positive impact of DCGAN.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me