Following are the two different ways which could be used to normalize the data, and thus, described later in this article:
- Why Normalize or Scale the data?
- Min-Max Normalization
- Z-Score Standardization
Why Normalize or Scale the data?
There can be instances found in data frame where values for one feature could range between 1-100 and values for other feature could range from 1-10000000. In scenarios like these, owing to the mere greater numeric range, the impact on response variables by the feature having greater numeric range could be more than the one having less numeric range, and this could, in turn, impact prediction accuracy. The objective is to improve predictive accuracy and not allow a particular feature impact the prediction due to large numeric value range. Thus, we may need to normalize or scale values under different features such that they fall under common range. Take a look at following example:
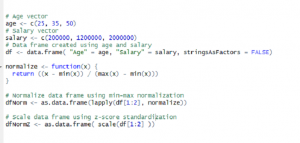
# Age vector age <- c(25, 35, 50) # Salary vector salary <- c(200000, 1200000, 2000000) # Data frame created using age and salary df <- data.frame( "Age" = age, "Salary" = salary, stringsAsFactors = FALSE)
Above data frame gets printed as follows:
Age Salary 1 25 200000 2 35 1200000 3 50 2000000
Pay attention to how values for age and salary varies in different ranges.
Min-Max Normalization
Above data frame could be normalized using Min-Max normalization technique which specifies the following formula to be applied to each value of features to be normalized. This technique is traditionally used with K-Nearest Neighbors (KNN) Classification problems.
(X - min(X))/(max(X) - min(X))
Above could be programmed as the following function in R:
normalize <- function(x) {
return ((x - min(x)) / (max(x) - min(x)))
}
In order to apply above normalize function on each of the features of above data frame, df, following code could be used. Pay attention to usage of lapply function.
dfNorm <- as.data.frame(lapply(df, normalize)) # One could also use sequence such as df[1:2] dfNorm <- as.data.frame(lapply(df[1:2], normalize))
In case, one wish to specify a set of features such as salary, following formula could be used:
# Note df[2] dfNorm <- as.data.frame(lapply(df[2], normalize)) # Note df["Salary"] dfNorm <- as.data.frame(lapply(df["Salary"], normalize))
Z-Score Standardization
The disadvantage with min-max normalization technique is that it tends to bring data towards the mean. If there is a need for outliers to get weighted more than the other values, z-score standardization technique suits better. In order to achieve z-score standardization, one could use R’s built-in scale() function. Take a look at following example where scale function is applied on “df” data frame mentioned above.
dfNormZ <- as.data.frame( scale(df[1:2] ))
Following gets printed as dfNormZ
Age Salary 1 -0.9271726 -1.03490978 2 -0.1324532 0.07392213 3 1.0596259 0.96098765

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
hi
very nice defined
Normalize Numeric Data using R, keep upthe good work
If working with dummy variables, should them also be normalized or should they be splitter when normalizing and after that, pasted again?