Last updated: 12th May, 2024
Data lakehouses are a relatively new concept in the data warehousing space. They combine the scalability and cost-effectiveness of cloud storage-based data lakes with the flexibility, security, and performance of traditional data warehouses to create a powerful data management solution. But what exactly is a data lakehouse, how does it work, and how might it be used in your organization? In this blog post, we’ll explore the basics of data lakehouses and provide real-world examples to illustrate their value.
What is a Data Lakehouse?
Simply speaking, data lakehouses combine elements from both data warehouses and data lakes — hence the name “data lakehouse” — to provide users with a single platform that can be used to store as in data lake while processing, analyzing, and visualizing large amounts of diverse data using data warehouse features such as high-performance SQL & schema. Data lakehouses came into existence because of the need to offer data lake-style benefits while leveraging warehouse-style features, such as SQL functionality and schema. Databricks first proposed the concept of Data Lake Houses. Data in Databricks is stored in the data lake while SQL engines process/access the data.
Some examples of data lakehouses include Amazon Redshift Spectrum or Delta Lake.
Delta Lake is an open-source storage framework that enables building a format-agnostic Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, Hive, Snowflake, Google BigQuery, Athena, Redshift, Databricks, Azure Fabric, and APIs for Scala, Java, Rust, and Python.
Amazon Redshift integrates with Amazon S3 (a data lake solution), allowing users to perform SQL queries across their S3 data using Redshift Spectrum. This integration effectively gives it lakehouse-like capabilities.
Here is a picture representing the similarities and differences between data warehouses, data lakes, and data lakehouses.
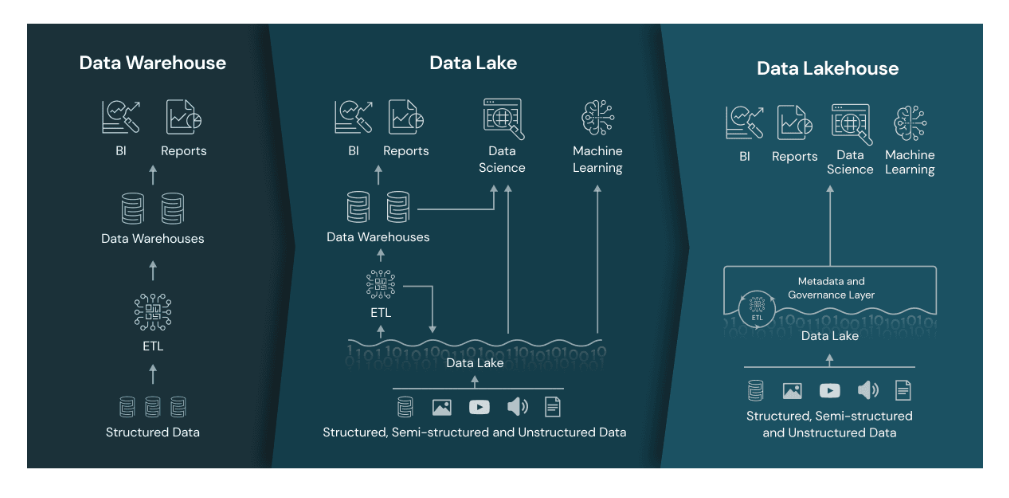
A data lakehouse is essentially a hybrid between a data warehouse and a cloud-based storage system, using both physical and virtual components to store vast amounts of structured and unstructured data. Unlike traditional data warehouses that rely on rigid schemas, data lakehouses are designed to be much more flexible, allowing organizations to quickly and easily add new datasets as needed without worrying about compatibility issues or long implementation times. The result is an efficient way to store large volumes of ever-changing data without sacrificing performance or reliability.
The line between data warehouses and data lakes got blurred due to data lakehouses. Here are some key functionalities of data lakehouses:
- Ability to store data like data lakes. Support for different data types in the structured or unstructured format
- Decoupling of storage and computing.
- Data warehouses like high-performance SQL on data lakes by using technologies like Presto and Spark (enabling SQL interface)
- Schema-like features on data lakes – File formats like Parquet are used to enable schema for data lake tables
- Atomicity, consistency, isolation, and durability (ACID): Technologies such as Apache Hudi and Delta Lake introduced greater reliability in write/read transactions
- Data governance including data access restriction.
- Native support of the typical multi-version approach of a data lake approach (i.e., bronze, silver, and gold)
Benefits of Data Lakehouses
Data lakehouses offer several key benefits over traditional data warehouses:
- Increased scalability: At its core, a data lakehouse is meant to provide organizations with the ability to scale up quickly as their needs grow. This makes them ideal for companies who need to quickly respond to changes in their business environment or process large volumes of dynamic customer or product information on demand.
- Improved performance: By leveraging both physical and virtual components, data lakehouses can provide superior performance compared to traditional warehouses while still keeping costs low. This makes them an attractive option for companies that need fast access to massive amounts of real-time information.
- Lower cost: Finally, one of the biggest advantages offered by data lakehouses is their lower cost compared to traditional systems. By utilizing cloud-based technology and leveraging existing hardware infrastructure, companies can save money on hardware purchases while still getting access to powerful analytics toolsets that help them gain valuable insights from their datasets.
Example Use Cases for Data Lakehouses
Data lakehouses can be used in virtually any industry where there’s a need for quick access to large quantities of diverse information—from healthcare providers who need rapid access to patient records and medical histories to retailers who require access to sales records across multiple outlets in order to make informed decisions around pricing strategies or inventory management.
Data lakehouses facilitate advanced analytics and machine learning by providing robust data storage and processing capabilities. Data scientists can train models directly on large datasets stored in a data lakehouse without moving data into separate analytics tools.
Conclusion
Data lakehouses are becoming increasingly popular due to their ability to combine the scalability of cloud storage with the performance and flexibility of traditional databases. They offer organizations the ability to quickly analyze vast amounts of structured and unstructured information while keeping costs low—a combination that makes them ideal solutions in many industries where timely access to accurate information is critical. If your organization needs quick access to massive amounts of diverse datasets, then you should definitely consider implementing a robust and secure data lakehouse solution today!

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me