In this post, you will learn how to convert Sklearn.datasets to Pandas Dataframe. It will be useful to know this technique (code example) if you are comfortable working with Pandas Dataframe. You will be able to perform several operations faster with the dataframe.
Sklearn datasets class comprises of several different types of datasets including some of the following:
- Iris
- Breast cancer
- Diabetes
- Boston
- Linnerud
- Images
The code sample below is demonstrated with IRIS data set. Before looking into the code sample, recall that IRIS dataset when loaded has data in form of “data” and labels present as “target”.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
# Load the IRIS dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Create dataframe using iris.data
df = pd.DataFrame(data=iris.data, columns=["sepal_length", "sepal_width", "petal_length", "petal_width"])
# Append class / label data
df["class"] = iris.target
# Print the data and check for yourself
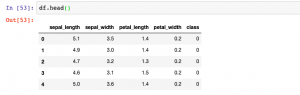
df.head()
Executing the above code will print the following dataframe.
In case, you don’t want to explicitly assign column name, you could use the following commands:
# Create dataframe using iris.data
df = pd.DataFrame(data=iris.data)
# Append class / label data
df["class"] = iris.target
# Print the data and check for yourself
df.head()
Conclusion
In this post, you learned about how to convert the SKLearn dataset to Pandas DataFrame.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me