In this post, we are going to learn about the cloud-native machine learning model deployments.
Cloud-native Deployments
First and foremost, let’s understand the meaning of cloud-native deployments? If we are building an application or a service and we can deploy this application or the service on any cloud platform without much ado, it could be said as cloud-native deployment. And the way it is made possible is through the container technologies such as Dockers. What basically is required to be done is to wrap the applications or the services within the containers and move the containers images onto the cloud services such as AWS ECS, AWS EKS or Google Kubernetes Engine, etc. The following are some of the important aspects of achieving the cloud-native deployments:
- Containerizing the applications: First and foremost, the application or the service would need to be wrapped within the container. It could also be called as containerizing the application or the service.
- Storing container images in container repositories: The next important thing is to identify the container repository. The main use of the container repository is to store the container images and maintain the versioning of these images. In the development environment, one could use a local container repository such as Nexus repository for or Jfrog repository. On the cloud platform, one could easily find the services which can help in storing the container images. The example of some of such services is AWS elastic container repository (ECR).
- Using container orchestration tool for the deployments: The next important thing is to set up a container orchestration development environment. The container orchestration tool such as kubernetes is unimportant tool adopted by many out there.
Once we have the container, container repository and the container orchestration tool we are ready for the cloud-native machine learning model deployments. In the next section, we will learn about how to use some of these technologies for or deploying r machine learning models on cloud platforms.
Cloud-native ML Model Deployments
The following diagram represents the cloud-native ML model deployments:
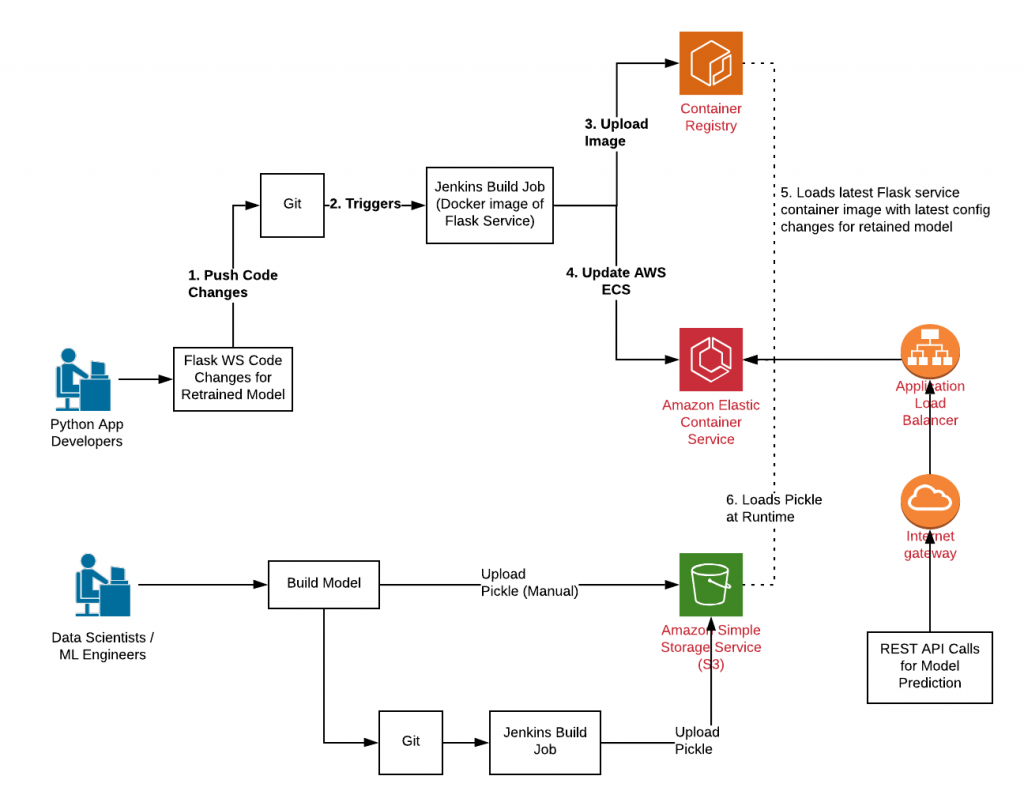
Fig 1. AWS ECS Cloud-native ML Model Deployments
For the cloud-native ML model deployments, the following are some of the important aspects:
- Machine learning engineers or data scientists working on building the models, optimizing the models’ performance, generating the pickle file, and uploading this pickle files on the cloud storage platform such as AWS S3. This workflow could also be achieved using tools such as GIT lab and the continuous integration tools such as Jenkins. In the diagram, you will see that the ML engineers build the model and commit and push the model code in the code repository such as GIT lab. As a result, a Jenkins build is triggered. As part of Jenkins build job the model is generated and pushed on the cloud storage platform such as AWS S3.
- Once the model is ready, the next step is to have the Python developers update the flask related code and configurations. Refer to the diagram for the details. The developers then push their code in the code repository such as GIT lab. As a result, Jenkins build is triggered. Jenkins build job results in some of the following:
- Running the build
- Building the container image
- pushing the container images on the cloud container repository service such as AWS ECR
- Updating the cloud container orchestration services such as AWS ECS. As soon as the cloud container services are updated, the existing containers are shut down based on some policies. New containers with the latest images uploaded in the container repository are started. As a result, the new container loads the latest pickle file uploaded in the cloud storage such as S3.
- The new requests are then served with prediction created using the latest pickle file.
Summary
In this post, we learned about how to use cloud services for deploying machine learning models. The main idea is to containerize the service such as flask service which loads pickle file from the cloud storage service and serves the request with the predictions.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me