Detecting bias in machine learning model has become of great importance in recent times. Bias in the machine learning model is about the model making predictions which tend to place certain privileged groups at a systematic advantage and certain unprivileged groups at a systematic disadvantage. And, the primary reason for unwanted bias is the presence of biases in the training data, due to either prejudice in labels or under-sampling/over-sampling of data. Especially, in banking & finance and insurance industry, customers/partners and regulators are asking the tough questions to businesses regarding the initiatives taken by them to avoid and detect bias. Take an example of the system using a machine learning model to decide those who could re-offend (Recidivism – the tendency of a convicted criminal to re-offend). You may want to check one of our related articles on understanding AI/Machine Learning Bias using Examples.
In this post, you will learn about bias detection technique using the framework, FairML, which could be used to detect and test the presence of bias in the machine learning models.
FairML – Bias Detection by Determining Relative Feature Importance
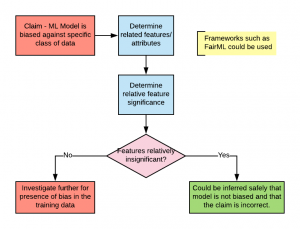
FairML adopts the technique of finding relative significance/importance of the features used in the machine learning model for detecting the bias in the model. In case the feature is one of the protected attributes such as gender, race, religion etc and found to have high significance, the model is said to be overly dependent on that feature. This implies that the feature (representing protected attributes) is playing important role in model’s prediction. Thus, the model could be said to be biased and hence, unfair. In case, the said feature is found to have low importance, the model dependence on that feature is very low and hence model could not be said to be biased towards that feature. The following diagram represents the usage of FairML for bias detection:

Fig 1. FairML for Bias Detection in Machine Learning Models
FairML Technique for Relative Feature Significance
In order to find the relative significance of the features, FairML makes use of the following four ranking algorithms to find feature significance/importance and evaluate combined ranking or feature significance using rankings of each of the following algorithms.
- Iterative orthogonal feature projection (IOFP)
- Minimum Redundancy, Maximum Relevance (mRMR)
- Lasso Regression
- Random forest
Iterative Orthogonal Feature Projection (IOFP)
This technique, iterative orthogonal feature projection, is implemented as the following:
- Calculate predictions of initial datasets without removing one or more protected attributes/features
- Identify the features representing the protected attribute/feature (such as gender, race, religion etc); Do the following for each of the identified features.
- Remove the data pertaining to that feature from all the input records
- Transform other features as orthogonal features to the feature (protected attribute) removed in above step.
- Calculate the predictions using transformed dataset (with the removed feature, and orthogonal features).
- Compare the predictions made using initial dataset and transformed dataset.
- Do the above for all those features which represent protected attributes.
If the difference between predictions made using initial dataset and transformed dataset (with removed feature/attribute and other features made orthogonal) is statistically significant, the feature could be said to be of high significance/importance.
Minimum Redundancy, Maximum Relevance (mRMR)
In this technique, the idea is to select features that correlate strongest to the target variable while being mutually far away from previously selected features. In the technique related to maximum relevance, those features are selected which correlate strongly with the target variable. However, at times, it is found that there are input features which are correlated with each other. However, it could be the case when one of these features is significant in relation to the prediction model. Other input feature, thus, act as redundant. The idea is to not include such redundant features. This is where this technique comes into the picture. Include features which have maximum relevance to the output variable but minimum redundancy with other input variables. Heuristic algorithms such as the sequential forward, backward, or bidirectional selections could be used to implement mRMR.
The mRMR ranking module in FairML was programmed in R leveraging the mRMRe package in the CRAN package manager
Lasso Regression
LASSO stands for Least Absolute Shrinkage Selection Operator. Linear regression uses Ordinary Least Squares (OLS) method to estimate the coefficients of the features. However, it has been found that the OLS method does result in low bias, high variance. As part of the regularization technique, the prediction accuracy is found to be improved by shrinking the coefficients of one or more of the insignificant parameters/features to bare minimum or near-to-zero (Ridge regression) or zero (LASSO regression). Ridge regression helps in estimating important features. However, LASSO regression helps in firming up the most important features as the non-significant features’ coefficient is set to 0.
For the LASSO ranking in FairML, the implementation provided through the popular Scikit-Learn package in python is leveraged.
Random Forest
Random Forest, one of the ensemble modeling technique, is used to determining the feature importance by making use of some of the following techniques:
- The depth of the attributes in the decision tree can be used to determine the importance of the attributes/features. Features higher in the tree could be thought of as affecting a significant portion of the total samples used to learn the tree model. Hence, they are termed as features of higher significance.
- Permute the value of attributes/features and determine the performance averaged across all the trees. If the attributes/features are highly significant, the change in accuracy would be high.
For the random forest ranking in FairML, the implementation provided through the popular Scikit-Learn package in python is leveraged.
References
- FairML – Github Project
- FairML: ToolBox for diagnosing bias in predictive modeling
- Minimum redundancy feature selection
Summary
In this post, you learned about the FairML framework and the technique used to determine the bias in the machine learning model. Primarily, if it is claimed that the model is biased against a specific class of data, FairML helps you determine the relative significance of the data representing those attributes and appropriately provide explanation against the claim.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me