In the artificial intelligence (AI) / machine learning (ML) powered world where predictive models have started getting used more often in decision-making areas, the primary concerns of policy makers, auditors and end users have been to make sure that these systems using the models are not making biased/unfair decisions based on model predictions (intentional or unintentional discrimination). Imagine industries such as banking, insurance, and employment where models are used as solutions to decision-making problems such as shortlisting candidates for interviews, approving loans/credits, deciding insurance premiums etc. How harmful it could be to the end users as these decisions may impact their livelihood based on biased predictions made by the model, thereby, resulting in unfair/biased decisions. Thus, it is important for product managers/business analysts and data scientists working on the ML problems to understand different nuances of model prediction bias such as some of the following which is discussed in this post.
What is ML Model Fairness/Bias?
Bias in the machine learning model is about the model making predictions which tend to place certain privileged groups at the systematic advantage and certain unprivileged groups at the systematic disadvantage. And, the primary reason for unwanted bias is the presence of biases in the training data, due to either prejudice in labels or under-sampling/over-sampling of data. Given that the features and related data used for training the models are designed and gathered by humans, individual (data scientists or product managers) bias may get into the way of data preparation for training the models. This would mean that one or more features may get left out, or, coverage of datasets used for training is not decent enough. In other words, the model may fail to capture essential regularities present in the dataset. As a result, the resulting machine learning models would end up reflecting the bias (high bias).
Machine learning model bias can be understood in terms of some of the following:
- Lack of an appropriate set of features may result in bias. In such a scenario, the model could be said to be underfitted. In other words, such models could be found to exhibit high bias and low variance.
- Lack of appropriate data set: Although the features are appropriate, the lack of appropriate data could result in bias. For a large volume of data of varied nature (covering different scenarios), the bias problem could be resolved. However, the caution has to be taken to avoid overfitting problem (high variance) which could impact the model performance in the sense that model would fail to generalize for all kind of datasets.
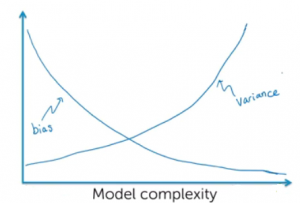
In case the model is found to have a high bias, the model would be called out as unfair and vice-versa. It should be noted that the attempt to decrease the bias results in high complexity models having high variance. The diagram given below represents the model complexity in terms of bias and variance. Note the fact that with a decrease in bias, the model tends to become complex and at the same time, may found to have high variance.
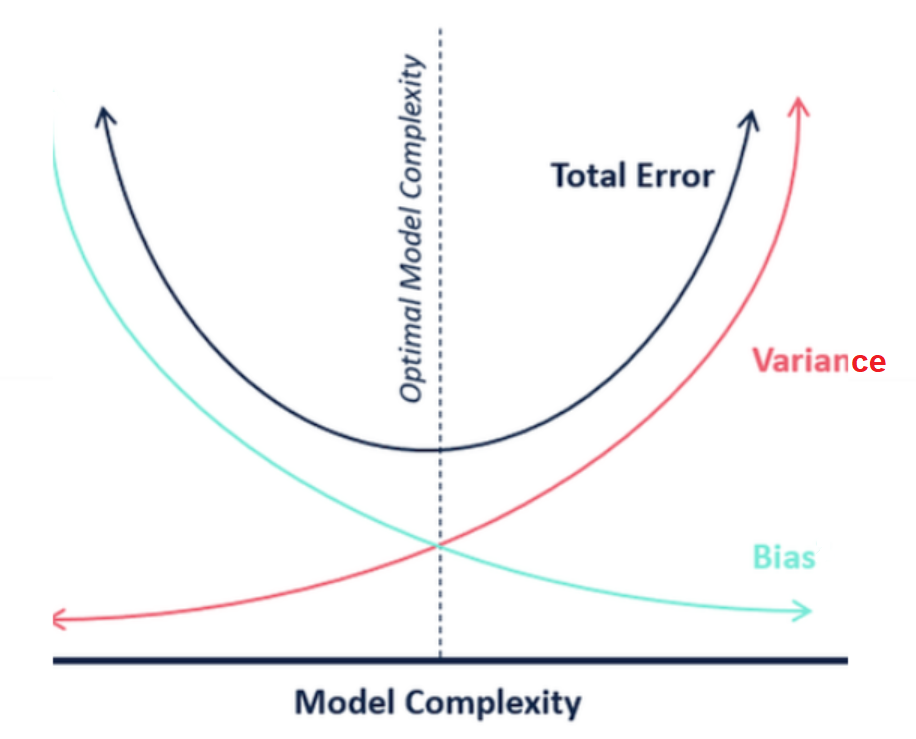
You may note some of the following in the above picture:
- Model having high bias may be a simple model.
- Model with high bias would high error rate.
- As the model bias decreases, there is a possibility that model will tend to become complex while overfitting the data. The model would end up having high variance.
- The objective is to find the sweet spot where model is optimal with most optimal error rate and not very complex model.
How to Test ML Model Fairness/Bias
It is important to understand how one could go about determining the extent to which the model is biased, and, hence unfair. One of the most common approaches is to determine the relative significance or importance of input values (related to features) on the model’s prediction/output. Determining the relative significance of input values would help ascertain the fact that the models are not overly dependent on the protected attributes (age, gender, color, education etc) which are discussed in one of the later sections. Other techniques include auditing data analysis, ML modeling pipeline etc. Accordingly, one would be able to assess whether the model is fair (unbiased) or not.
In order to determine the model bias and related fairness, some of the following frameworks could be used:
Bias-related Features / Attributes
The following are some of the attributes/features which could result in bias:
- Race
- Gender
- Color
- Religion
- National origin
- Marital status
- Sexual orientation
- Education background
- Source of income
- Age
One would want to adopt appropriate strategies to train and test the model and related performance given the bias introduced due to data related to the above features.
Examples – Industries being impacted by AI Bias
The bias (intentional or unintentional discrimination) could arise in various use cases in industries such as some of the following:
- Banking: Imagine a scenario when a valid applicant loan request is not approved. This could as well happen as a result of bias in the system introduced to the features and related data used for model training such as gender, education, race, location etc. In another example, imagine an applicant whose loan got approved although he is not suitable enough. In yet another example, imagine an applicant credit card application getting rejected although the applicant was a valid applicant who satisfied all the requirements for getting the credit card. It may so happen that the model used to classify the credit card application to be approved or rejected had an underlying bias owing to educational qualification of the applicants.
- Insurance: Imagine a person being asked to pay a higher premium based on the predictions made by the model which took into account some of the attributes such as gender, race for making the predictions.
- Employment: Imagine a machine learning model inappropriately filtering the candidates resumes based on the attributes such as race, color etc of the candidates. This could not only impact the employability of the right candidates but also results in the missed opportunity of the company to hire a great candidate.
- Housing: Imagine a model with a high bias making incorrect predictions of house pricing. This may result in both, the house owner and the end user (the buyer) miss the opportunity related to buy-sell. The bias may get introduced due to data related to location, community, geography etc.
- Fraud (Criminal/Terrorist): Imagine the model incorrectly classifying a person as the potential offender and getting him/her questioned for the offense which he/she did not do. That could be the predictable outcome of a model which may be biased towards race, religion, national origin etc. For example, in certain countries or geographies, a person of a specific religion or national origin is suspected to perform a certain kind of crime such as terrorism. Now, this becomes part of individual bias. This bias gets reflected in the model prediction.
- Government: Imagine government schemes to be provided to a certain section of people and machine learning models being used to classify these people who would get benefits from these schemes. A bias would result in either some eligible people not getting the benefits (false positives) or some ineligible people getting the benefits (false negatives).
- Education: Imagine an applicant admission application getting rejected due to underlying machine learning model bias. The bias may have resulted due to data using which model was trained.
- Finance: In the financial industry, the model built with the biased data may result into predictions which could offend the Equal Credit Opportunity Act (fair lending) by not approving credit request of right applicants. And, the end users could challenge the same requiring the company to provide an explanation for not approving the credit request. The law, enacted in 1974, prohibits credit discrimination based on attributes such as race, color, religion, gender etc. While building models, product managers (business analysts) and data scientists do take steps to ensure that correct/generic data (covering different aspects) related to some of the above-mentioned features have been used to build (train/test) the model, the unintentional exclusion of some of the important features or data sets could result in bias.
References
- Bias-Variance Trade-off
- Bias-Variance in Machine Learning
- Risk of Machine Learning Bias and how to prevent it
Summary
In this post, you learned about the concepts related to machine learning models bias, bias-related attributes/features along with examples from different industries. In addition, you also learned about some of the frameworks which could be used to test the bias. Primarily, the bias in ML models results due to bias present in the minds of product managers/data scientists working on the machine learning problem. They fail to capture important features and cover all kinds of data to train the models which result in model bias. And, a machine learning model with high bias may result in stakeholders take unfair/biased decisions which would, in turn, impact the livelihood & well-being of end customers given the examples discussed in this post. Thus, it is important that the stakeholders pay importance to test the models for the presence of bias.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me