Large language models (LLMs), also termed large foundation models (LFMs), in recent times have been enabling the creation of innovative software products that are solving a wide range of problems that were unimaginable until recent times. Different stakeholders in the software engineering and AI arena need to learn about how to create such LLM-powered software applications. And, the most important aspect of creating such apps is the application architecture of such LLM applications.
In this blog, we will learn about key application architecture components for LLM-based applications. This would be helpful for product managers, software architects, LLM architects, ML engineers, etc. LLMs in the software engineering landscape are also termed as the reasoning engine.
You might want to check this book to learn more – Building LLM-powered applications.
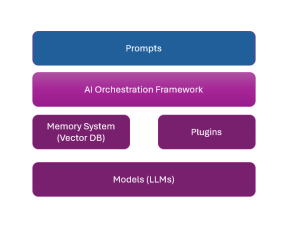
Key LLM Application Architecture Components
The following are the key application architectural components of LLM-powered applications:
- Prompts: Prompts form one of the most important aspects of LLM-powered applications. They represent user instructions in the form of natural text, passed to the application. Prompts represent input to the LLMs. Apart from prompts entered by the user, some meta-prompts are attached to the user prompts and passed as a whole to the LLM.
- Models (LLMs): Two kinds of LLMs are used in LLM applications.
- One of them is proprietary LLMs which are foundation LLMs trained by commercial organizations such as OpenAI (GPT-3, GPT-4, etc) or Google (Gemini). These models can’t be retrained from scratch. However, they can be fine-tuned.
- The other kind of models are open-source LLMs whose code and architecture are freely available. They can be trained from scratch using custom data. LLama by Meta or Falcon LLM by TII are examples of such models.
- Memory: One of the key aspects of the LLM application is the usage of ongoing conversations for generating LLM output. These conversations happen using a conversational user interface where the user enters prompts. The output of LLM applications gets enriched if the information in past conversations can be referred to. This is where a system termed a memory system comes into play. It allows the LLM application to store and retrieve past conversations. The memory system used in the LLM application is a vector database (Vector DB). Some examples of Vector DBs include Chroma, Elasticsearch, Milvus, Pinecone, Qdrant, Weaviate, and Facebook AI Similarity Search (FAISS).
The following is a snapshot of how conversation data is stored and retrieved from a vector database:- Every conversation is converted into a numerical vector using the preferred embedding models such as BERT, GPT, etc.
- The numerical vectors are then stored in the vector database.
- The current prompt is converted into vector representation when required to retrieve a set of conversations. A similarity search is performed on the vector database to find the most relevant conversations. These conversations act as a context to feed the LLM to retrieve the contextually relevant response.
- AI orchestration framework: The AI orchestration framework represents lightweight libraries that make it easier to embed and orchestrate LLMs within applications. Three of the most popular AI orchestration frameworks are LangChain, HayStack, and Semantic Kernel.
- Plugins: Plugins represent add-on application components that help LLM applications extend functionality beyond core language generation or comprehension abilities.
Source Code Example representing LLM Application Architecture Components
The following code uses LanChain as an AI orchestration framework and is used to interact with embedding models, vector databases, LLM providers (such as OpenAI), etc.
Prompt converted to vector representation: The prompts once entered by the users are converted into a vector representation. The following is a sample code:
from langchain.embeddings import HuggingFaceEmbeddings
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
prompt_vector = embedding_model.embed(prompt)
Similarity search from Vector DB to retrieve context: Use the generated prompt vector in the above step to perform a similarity search in the vector database (e.g., Pinecone, FAISS, Milvus) to retrieve relevant past conversations.
from langchain.vectorstores import Pinecone
vector_store = Pinecone(api_key='your_api_key', index_name='conversation_index')
relevant_conversations = vector_store.similarity_search(prompt_vector, top_k=5)
Context creation: Retrieve the most relevant past conversations and process them to create a context for the LLM. This could involve concatenating the retrieved conversations or using a more sophisticated method to combine them.
context = "\n".join([conv['text'] for conv in relevant_conversations])
Generate the response from LLM: Pass the combined context along with the new prompt to the LLM to generate a response.
from langchain.llms import OpenAI
llm = OpenAI(api_key='your_openai_api_key')
full_prompt = f"{context}\nUser: {prompt}\nAssistant:"
response = llm.generate(full_prompt)
user_response = response['choices'][0]['text']

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025
- RAG Pipeline: 6 Steps for Creating Naive RAG App - November 1, 2025
I found it very helpful. However the differences are not too understandable for me