In this post, you will learn about different types of classification machine learning algorithms that are used for building models.
Here are four different classes of machine learning algorithms for solving classification problems:
- Probabilistic modeling
- Kernel methods
- Trees based algorithms
- Neural network
Probabilistic Modeling Algorithms
Probabilistic modeling is about modeling probability of whethar a data point belongs to one class or the other. In case of need to train machine learning models to classify a data point into multiple classes, probabilistic modeling approach will let us model the probability of a data point belonging to a particular class. Mathematically, it can be represented as P(C|X) and read as probability of class C happening given data X happened. In other words, P(C|X) denotes the probability of data X belonging to class C.
In probabilistic modeling approach, if there are two classes say C1 and C2, then, the higher of the probability P(C1 | X) and P(C2 | X) represents the class to which data X belongs. If the data can belong to just one class, then conventionally, the probability that the data X belongs to a particular class is determined and based on a threshold, it is predicted whether the data belong to one class or the other.
Machine learning algorithms such as Logistic Regression and Naive Bayes is classical example of probabilistic modeling.
Kernel Methods
Kernel methods aims at solving classification problems by finding good decision boundaries between two sets of points belonging to two different categories. The diagram below represents the decision boundaries:
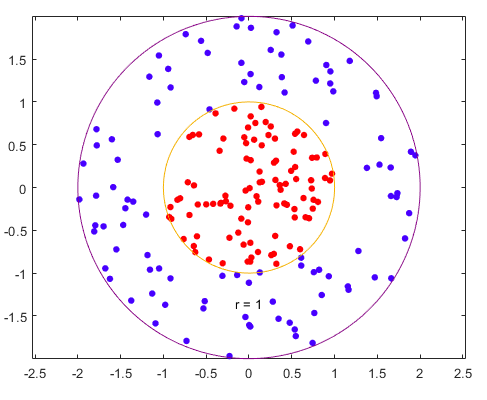
Fig 1. Using Kernel method for finding decision boundaries
One of the most popular algorithm related to Kernel method is Support Vector Machines (SVM). In SVM algorithm, the idea is to map the data to a new high-dimensional representation where the decision boundary can be expressed as a hyperplane. The diagram below represents the same.
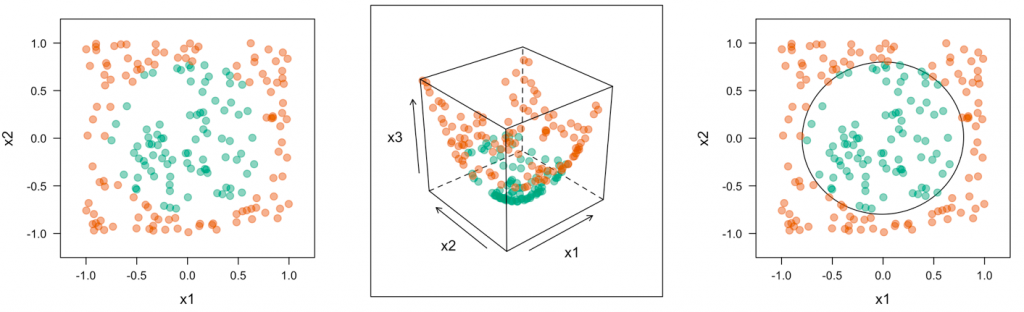
Fig 2. Kernel Method – Transform Input data into Higher Dimensional Space
A kernel function maps any two points in the initial space to the distance between these points in the target representation space and does not require the explicit computation of the new representation. These functions are crafted by hand rather than learned from data. As in the case of an SVM, only the separation hyperplane is learned.
Tree-based Algorithms
Trees-based algorithms are also used to solve classification problems. Different trees-based algorithms include decision tree, random forest and gradient boosting machines (GBM). What is learnt in the tree based algorithms are decision criteria of different nodes of the tree. For ensemble methods such as random forest and GBM based implementation, different parameters are learned.
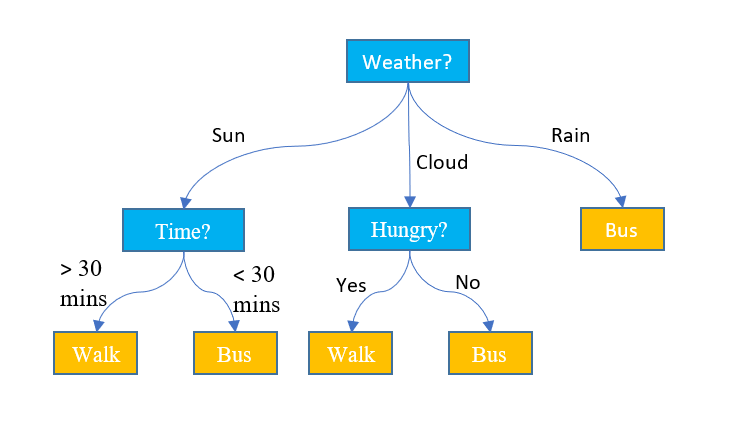
Fig 3. Example of a Decision Tree
Random forest is about creating large number of decision trees and making the final prediction based on ensembling the outputs from each tree.
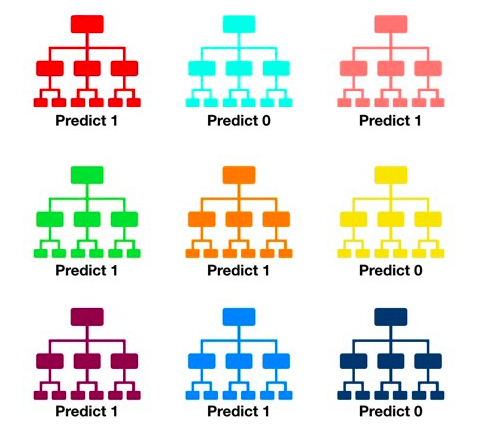
Fig 4. Random forest
Another technique is gradient boosting machine. It is much like a random forest, is a machine-learning technique based on ensembling weak prediction models, generally decision trees.
Neural Networks
Another class of algorithms used for solving classification problem are neural network. Neural network can be trained using shallow learning or deep learning technique based on number of layered representations. The following represents the neural network.
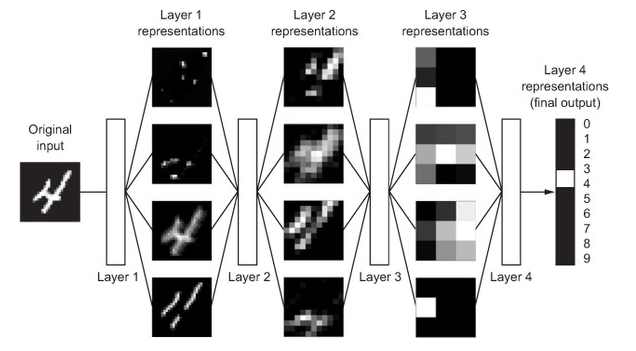
Fig 5. Deep learning network used for classifying digits

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me