Tag Archives: data engineering
Data Ingestion Types – Concepts & Examples
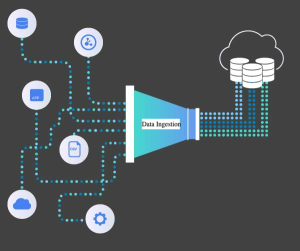
Last updated: 17th Nov, 2023 Data ingestion is the process of moving data from its original storage location to a data warehouse or other database for analysis. Data engineers are responsible for designing and managing data ingestion pipelines. Data can be ingested in different modes such as real-time, batch mode, etc. In this blog, we will learn the concepts about different types of data ingestion with the help of examples. What is Data Ingestion? Data ingestion is the foundational process of importing, transferring, loading, and processing data from various sources into a storage medium where it can be accessed, used, and analyzed by an organization. It’s akin to the first …
Open Source Web Scraping Tools List
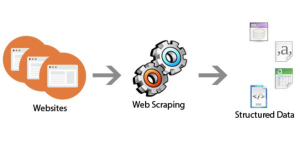
If you’re looking for a cost-effective way to access the data that matters most to your business, then web scraping is the answer. Web scraping is the process of extracting data from websites and can be used to gather valuable insights about market trends, customer behavior, competitor analysis, etc. To make this process easier, there are plenty of open source web scraping tools available. Let’s take a look at some of these tools and how they can help you collect and analyze data with greater efficiency. Beautiful Soup Beautiful Soup is a Python library designed for quick turnaround projects like screen-scraping. This library allows you to parse HTML and XML …
ETL & Data Quality Test Cases & Tools: Examples

Testing the data that is being processed from Extract, Transform and Load (ETL) processes is a critical step in ensuring the accuracy of data contained in destination systems and databases. This blog post will provide an overview of ETL & Data Quality testing including tools, test cases and examples. What is ETL? ETL stands for extract, transform, and load. ETL is a three-step process that is used to collect data from various sources, prepare the data for analysis, and then load it into a target database. The extract phase involves extracting data from its original source, such as a database or file system. The transform phase involves transforming this data …
Amazon Kinesis vs Kafka: Concepts, Differences
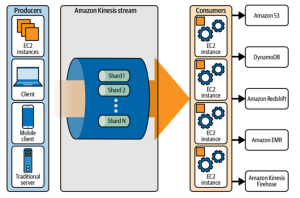
As technology advances, new data streaming solutions emerge to meet the ever-growing demand for real-time analytics. Two popular options are Amazon Kinesis and Apache Kafka. Here, we’ll take a look at these two platforms and compare them in terms of their core concepts and differences. What is Amazon Kinesis? Amazon Kinesis is an AWS serverless streaming service that allows you to collect, process, and analyze streaming data in real time. It is a fully managed service that can capture, store, and analyze hundreds of terabytes of data from millions of sources simultaneously. It is designed to be highly available and scalable so that your streaming data can be reliably processed …
Data Quality Challenges for Analytics Projects

In this post, you will learn about some of the key data quality challenges which you may need to tackle with, if you are working on data analytics projects or planning to get started on data analytics initiatives. If you represent key stakeholders in analytics team, you may find this post to be useful in understanding the data quality challenges. Here are the key challenges in relation to data quality which when taken care would result in great outcomes from analytics projects related to descriptive, predictive and prescriptive analytics: Data accuracy / validation Data consistency Data availability Data discovery Data usability Data SLA Cos-effective data Data Accuracy One of the most important …
Data Science vs Data Engineering Team – Have Both?

In this post, you will learn about different aspects of data science and data engineering team and also understand the key differences between them. As data science / engineering stakeholders, it is very important to understand whether we need to have one or both the teams to achieve high quality dataset & data pipelines as well as high-performant machine learning models. Background When an organization starts on the journey of building data analytics products, primarily based on predictive analytics, it goes on to set up a centralized (mostly) data science team consisting of data scientists. The data science team works with the product team or multiple product teams to gather the …

I found it very helpful. However the differences are not too understandable for me