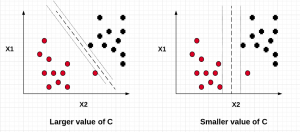
In this post, we will understand the importance of C value on the SVM soft margin classifier overall accuracy using code samples. In the previous post titled as SVM as Soft Margin Classifier and C Value, the concepts around SVM soft margin classifier and the importance of C value was explained. If you are not sure about the concepts, I would recommend reading earlier article.
Lets take a look at the code used for building SVM soft margin classifier with C value. The code example uses the SKLearn IRIS dataset
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import datasets
# Load IRIS Data set
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Create train and test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify = y)
# Feature scaling
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
# Train the model; We will train different models using different value of C
svm = SVC(kernel= 'linear', random_state=1, C=0.01)
svm.fit(X_train_std, y_train)
# Measure accuracy score
y_pred = svm.predict(X_test_std)
print('Accuracy: %.3f' % accuracy_score(y_test, y_pred))
In the above code example, take a note of the value of C = 0.01. The model accuracy came out to be 0.822. For different values of C, the model accuracy changed. As the value of C increased, the model accuracy increased resulting in lesser misclassifications. The table given below displays different value of model accuracy for different value of C.
| C Value | Model Accuracy |
| 0.01 | 0.822 |
| 0.02 | 0.867 |
| 0.03 | 0.889 |
| 0.1 | 0.978 |
You may note that as the value of C increases, the model accuracy increases. However, there is a likelihood of model overfitting (high variance) which needs to be evaluated. An appropriate value of C can be found using cross-validation method which will be discussed in the future post.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me