In this post, you will learn about tips and techniques which could be used for selecting or choosing the right machine learning algorithms for your machine learning problem. These could be very useful for those data scientists or ML researcher starting to learn data science/machine learning topics.
Based on the following, one could go for selecting different classes of machine learning algorithms for training the models.
-
Availability of data
-
Number of features
This post deals with the following different scenarios while explaining machine learning algorithms which could be used to solve related problems:
-
A large number of Features, Lesser Volume of Data
-
A smaller number of Features, Large Volume of Data
-
A large number of Features, Large Volume of Data
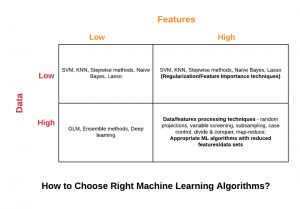
A Large number of Features, Lesser Volume of Data
For scenarios where there are a large number of features but a lesser volume of data, one could go for some of the following machine learning algorithms:
-
Stepwise methods
-
Lasso regression analysis
-
Support vector machine (SVM)
-
K-NN
- Naive Bayes
A larger number of features generally result in overfitting of the models. Thus, one of the key exercise in such a scenario is to do one or both of the following:
-
Remove lesser important features; One could use feature selection techniques to achieve the same.
-
Apply L1 or L2 regularization method for penalizing the weights associated with each feature.
One of the example where you would find a large number of features but a lesser volume of data is protein-to-protein interactions. In protein-to-protein interactions, the number of features can be in the order of millions, but the sample size can be in the order of thousands.
A Smaller number of Features, Large Volume of Data
For scenarios where there are a smaller number of features but a large volume of data, one could go for some of the following machine learning algorithms:
-
Generalized linear models (GLM)
-
Ensemble methods such as bagging, random forest, boosting (AdaBoost)
-
Deep learning
The examples of large data could include microarrays (gene expression data), proteomics, brain images, videos, functional data, longitudinal data, high-frequency financial data, warehouse sales, among others.
A Large number of Features, Large Volume of Data
For scenarios where there are a larger number of features and a large volume of data, the primary concern becomes the computational cost for data processing and training/testing the models. The following represents some of the techniques which could be used for processing a large number of features and associated data set while building the models:
-
Random projections: A technique used to reduce the dimensionality of a set of points which lie in Euclidean space; The technique is used to reduce the features to the most important ones
-
Variable screening: Variable screening methods are used to select the most important features out of all.
-
Subsampling: With a large dataset, the computational cost savings is achieved by subsampling the data sets. The idea behind subsampling is to fit the model to the subsample and make an equally simple correction to obtain an estimate for the original data set. However, the problem arises when the subsampling fails to take into account the imbalanced data set having the class imbalance. If taken care, it could help achieve significant computational cost savings. The following represents different forms of imbalanced class data sets:
-
Marginal imbalance: The data representing one or more of the classes are very less in numbers. For example, let’s say for every thousand positive examples, there are a couple of negative examples.
-
Conditional imbalance: For the most value of features set, the prediction is easier and accurate than others set of input features. In order to take care of the imbalanced class problem, the technique used is called case-control sampling.
-
-
Case-control sampling: Case-control sampling technique is used to gather a uniform sample for each class while adjusting the mixture of the classes. This technique is used to reduce the complexity of training a logistic regression classifier. The algorithm reduces the training complexity by selecting a small subsample of the original dataset for training. A logistic regression model fitted on the subsample can be converted to a valid model for the original population via a simple adjustment to the intercept. Standard case-control sampling still may not make the most efficient use of the data. It fails to efficiently exploit conditional imbalance in a data set that is marginally balanced.
-
MapReduce
-
Divide and conquer
Once the aspects related to a large number of features or a large volume of data set is taken care, one could appropriately use different algorithms as described above.
References
Summary
In this post, you learned about the selection criteria of different machine learning algorithms and appropriate data processing techniques based on a number of features and volume of data. For a larger number of features and a smaller volume of data, one could go for algorithms such as SVM, lasso regression methods, stepwise methods etc. For a smaller number of features and larger volume of data, one could go for GLM, deep learning algorithms, ensemble methods etc. For the larger volume of features and data, first and foremost, it is recommended to bring down the number of features to the most important features and secondly, use subsampling techniques for computational cost savings. One could then apply the appropriate ML algorithms as described in this post.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me