In this post, you will get Python code sample using which you can search Reddit for specific subreddit posts including hot posts. Reddit API is used in the Python code. This code will be helpful if you quickly want to scrape Reddit for popular posts in the field of machine learning (subreddit – r/machinelearning), data science (subreddit – r/datascience), deep learning (subreddit – r/deeplearning) etc.
There will be two steps to be followed to scrape Reddit for popular posts in any specific subreddits.
- Python code for authentication and authorization
- Python code for retrieving the popular posts
Check the Reddit API documentation page to learn about Reddit APIs.
Python code for Authentication / Authorization
Here is the code you would need to use for authenticating and authorization purposes. Here are the key steps:
- Open an account in the reddit. The username and password will be used with login method having grant type as password.
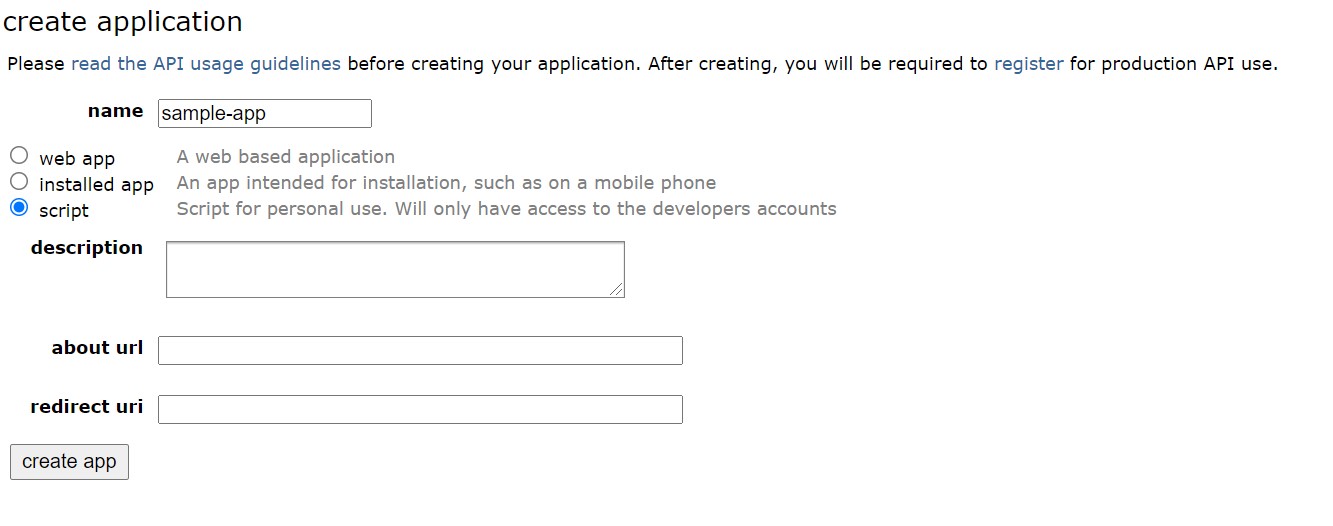
- Create an app by visiting the app page. Select the option script if you want to invoke the app from the Python script
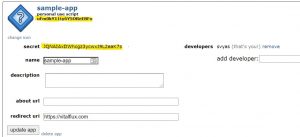
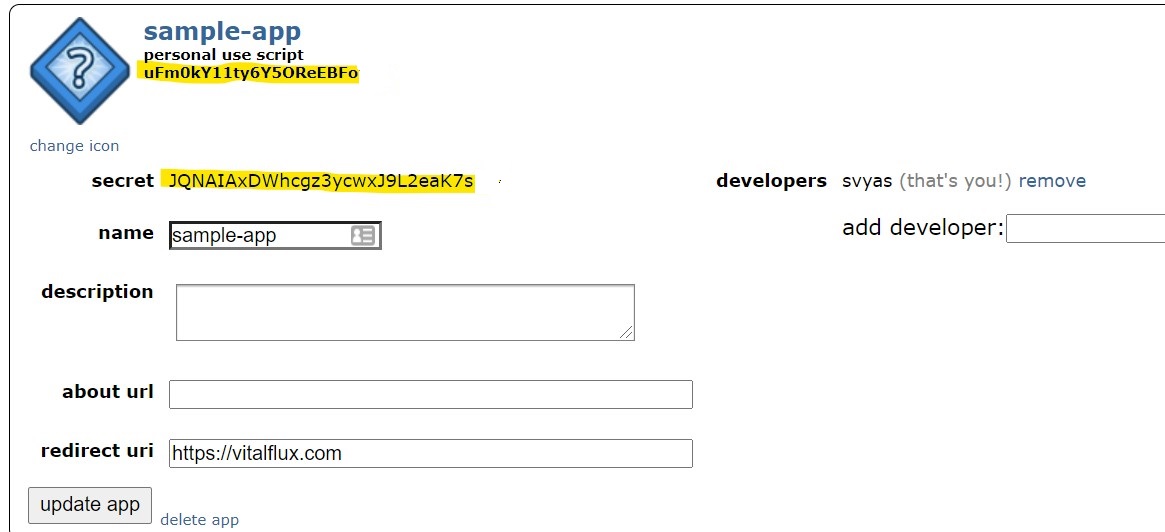
- Note the CLIENT_ID (as personal use script) and SECRET_TOKEN (as secret) in the image depicted with yellow color.
- With above steps done, you are all set. Paste this code in your Jupyter notebook and execute to get the token which will be used to retrieve the subreddits popular posts.
import requests
# note that CLIENT_ID refers to 'personal use script' and SECRET_TOKEN to 'token'
auth = requests.auth.HTTPBasicAuth('qfK5a5tkC-bkV3adVR5d2w', 'AX01I3U9WQ4eSkGfK67kk4AEgkIKbM')
# here we pass our login method (password), username, and password
data = {'grant_type': 'password',
'username': 'vitalflux',
'password': 'vitalflux'}
# setup our header info, which gives reddit a brief description of our app
headers = {'User-Agent': 'vitalflux-pybot/0.0.1'}
# send our request for an OAuth token
res = requests.post('https://www.reddit.com/api/v1/access_token',
auth=auth, data=data, headers=headers)
# convert response to JSON and pull access_token value
TOKEN = res.json()['access_token']
# add authorization to our headers dictionary
headers = {**headers, **{'Authorization': f"bearer {TOKEN}"}}
Python code for retrieving the popular posts
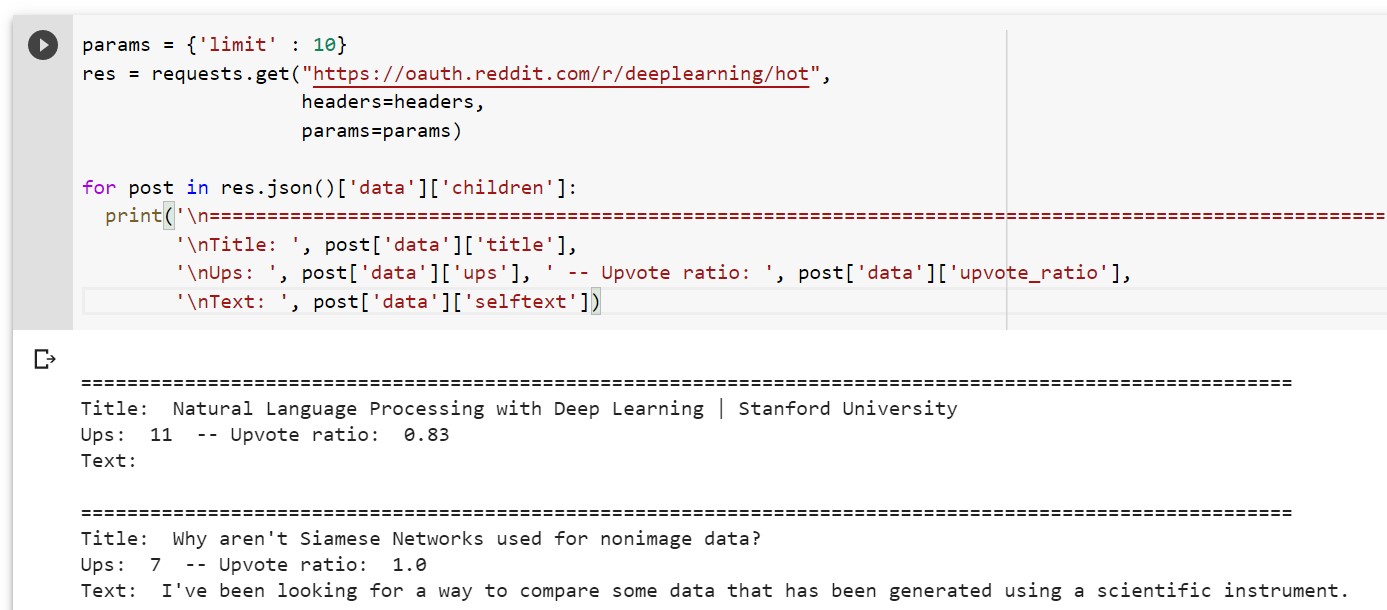
- Paste the following code to retrieve the popular (hot) posts for specific subreddit. In the code below, the subreddit, deeplearning is used. Make a note of params which is used to limit the number of posts which need to be retrieved. In the example below, the limit is set to 10.
params = {'limit' : 10}
res = requests.get("https://oauth.reddit.com/r/deeplearning/hot",
headers=headers,
params=params)
for post in res.json()['data']['children']:
print('\n=========================================================================================================',
'\nTitle: ', post['data']['title'],
'\nUps: ', post['data']['ups'], ' -- Upvote ratio: ', post['data']['upvote_ratio'],
'\nText: ', post['data']['selftext'])
The following is what gets printed.
Putting it all together
Here is the entire Python code which can be used to retrieve the subreddit’s popular posts. Ensure to put your own username/password and, client id/secret token
import requests
# note that CLIENT_ID refers to 'personal use script' and SECRET_TOKEN to 'token'
auth = requests.auth.HTTPBasicAuth('qfK5a5tkC-bkV3adVR5d2w', 'AX01I3U9WQ4eSkGfK67kk4AEgkIKbM')
# here we pass our login method (password), username, and password
data = {'grant_type': 'password',
'username': 'vitalflux',
'password': 'vitalflux'}
# setup our header info, which gives reddit a brief description of our app
headers = {'User-Agent': 'vitalflux-pybot/0.0.1'}
# send our request for an OAuth token
res = requests.post('https://www.reddit.com/api/v1/access_token',
auth=auth, data=data, headers=headers)
# convert response to JSON and pull access_token value
TOKEN = res.json()['access_token']
# add authorization to our headers dictionary
headers = {**headers, **{'Authorization': f"bearer {TOKEN}"}}
# Print the subreddit popular posts
params = {'limit' : 10}
res = requests.get("https://oauth.reddit.com/r/deeplearning/hot",
headers=headers,
params=params)
for post in res.json()['data']['children']:
print('\n=========================================================================================================',
'\nTitle: ', post['data']['title'],
'\nUps: ', post['data']['ups'], ' -- Upvote ratio: ', post['data']['upvote_ratio'],
'\nText: ', post['data']['selftext'])

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me