This is the first post in the series of posts related to Quality Assurance & Testing Practices and Data Science / Machine Learning Models which I would release in next few months. The goal of this and upcoming posts would be to create a tool and framework which could help you design your testing/QA practices around data science/machine learning models.
Why QA Practices for testing Machine Learning Models?
Are you a test engineer and want to know about how you could make difference in AI initiative being undertaken by your current company? Are you a QA manager and looking for or researching tools and frameworks which could help your team perform QA with machine learning models built by data scientists? Are you on one of the strategic role in your company and looking for QA practices (to quality assure ML models built by data scientists) which you want to be adopted in your testing center of excellence (COE) to serve your clients in a better manner?
If the answer to above is yes, come along with me on this ride. I would be presenting concepts, tools, and frameworks which would help you achieve some of the objectives mentioned earlier.
I have seen in my experience that ML models are developed and tested by the data scientists themselves. This is not a desired situation to be in. Ideally speaking, it should be a quality assurance team which should be performing QA by running tests as like traditional software to test the ML models from time-to-time. However, the challenge is that ML models are not like traditional software where the behavior of the software is pre-determined based on the different inputs. We will touch upon some of the challenges related to testing ML model in later articles.
What can all be tested with ML Models?
The following are some of the aspects of a machine learning model which needs to be tested / quality assured:
-
Quality of data
-
Quality of features
-
Quality of ML algorithms
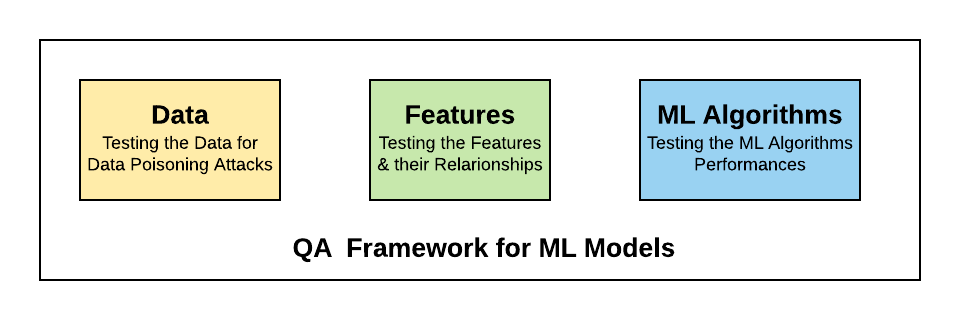
Figure 1. QA Framework for testing Machine Learning Models
Quality Assurance of Data used for Training the Model
One of the most overlooked (or ignored) aspects of building a machine learning model is to check whether the data used for training and testing the model are sanitized or, they belong to an adversary data set. The adversary data sets are the ones which could be used to skew the results of the model by training the model using wrong / incorrect data. This is also termed as data poisoning attacks.
The role of the QA is to put test mechanisms in place to validate whether the data used for training is sanitized; In other words, the tests need to be performed to identify whether there are instances of data poisoning attacks intentionally or unintentionally.
In order to achieve above, one of the techniques could be to have QA/Test engineers work with product management and product consultant teams for some of the following:
-
Understand the statistics related with data (mean, median, mode etc)
-
Understand the data and their relationships at a high-level
-
Build tests (using scripts) to check the above statistics and relationships.
-
Run the tests at regular intervals
The parameters such as above would need to be tracked at regular intervals and verified with the help of PMs/consultants before every release. We will go into the details in later articles.
Quality Assurance of Features
Many a time, one or more features could cease to be important or become redundant/irrelevant, and, in turn, impact the prediction error rates. This is where a set of QA/testing practice should be in place to proactively evaluate features using feature engineering techniques such as feature selection, dimensionality reduction etc. We will go into the details in later articles.
Quality Assurance of ML algorithms
Evolving datasets as a result of business evolution or data poisoning attacks could result in increased prediction error rates. As the ML model gets retrained (manually or in an automated manner), the increased prediction error rates result in the re-evaluation of ML model which could result in the discovery of new algorithm which could give improved accuracy over the previous ones.
One of the ways to go about testing ML algorithms with new data is the following:
-
Keep all the ML models based on different algorithms handy. Many a time, I have seen that ML models built using different algorithm get discarded once and for all after the most accurate model gets selected.
-
Retrain all of the models and evaluate the performance
-
Track the performance of all the models with new data set at regular intervals.
-
Raise the defect if another model starts giving greater accuracy or performing better than the existing model.
We will go into further details in later articles.
References
Summary
In this post, you learned about the need for QA practices for Data Science / ML models and also the different aspects of testing the ML models. Please feel free to suggest or share your thoughts.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me