This article represents details on whether to use single datastore per microservice. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos.
From what I researched, the preferred architecture for microservices is polyglot persistence pattern. (http://martinfowler.com/bliki/PolyglotPersistence.html ). You could further read about this on following pages:
- http://martinfowler.com/articles/microservices.html#DecentralizedDataManagement
- http://microservices.io/patterns/data/database-per-service.html
As per the best practices, each micro-service should have one database private to it. There are different ways to achieve the above objective. Some of them are listed below:
- Same database system for different services. In this following could be done:
- Different set of tables specific to microservice in the same database
- Different database schema but in the same database server
- Different database server
- Each service can use different database systems. For example, RDBMS, MongoDB etc.
Following diagram represents one datastore per microservice. (courtesy: MartinFowler page on MSA)
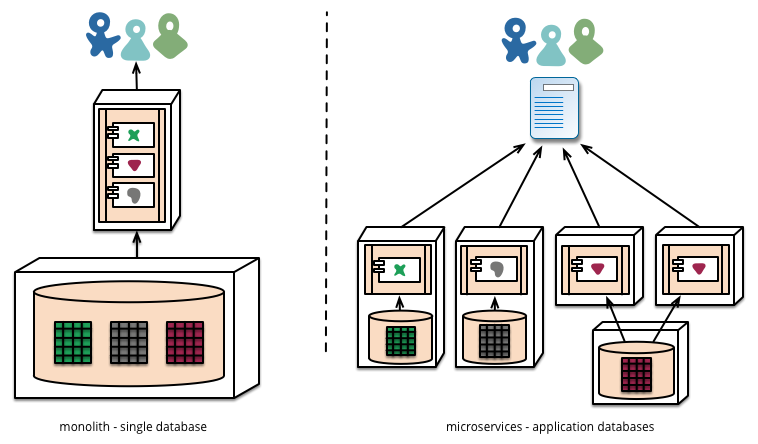
Following is another page representing MSA best practices from NetFlix. It highlights creating separate datastore for each microservice.
https://www.nginx.com/blog/microservices-at-netflix-architectural-best-practices/

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning and BI. I would love to connect with you on Linkedin.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Latest posts by Ajitesh Kumar (see all)
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me