Language models are models which assign probabilities to a sentence or a sequence of words or, probability of an upcoming word given previous set of words. Language models are used in fields such as speech recognition, spelling correction, machine translation etc. Language models are primarily of two kinds:
- N-Gram language models
- Grammar-based language models such as probabilistic context-free grammars (PCFGs)
In this post, you will learn about some of the following:
- Introduction to Language Models
- N-Grams language models
Introduction to Language Models
Language models, as mentioned above, is used to determine the probability of occurrence of a sentence or a sequence of words. Language models are created based on following two scenarios:
Scenario 1: The probability of a sequence of words is calculated based on the product of probabilities of each word. Let’s say, we need to calculate the probability of occurrence of the sentence, “car insurance must be bought carefully”. The probability of occurrence of this sentence will be calculated based on following formula:
[latex]P(car\text{ }insurance\text{ }must\text{ }be\text{ }bought\text{ }carefully) = [/latex]
[latex]P(car)*P(insurance)*P(must)*P(be)*P(bought)*P(carefully)[/latex]
In above formula, the probability of each word can be calculated based on following:
[latex]P(car)=\frac{No.\text{ }of\text{ }times\text{ }word\text{ }car\text{ }occurred\text{ }in\text{ }the\text{ }corpus)}{total\text{ }no\text{ }of\text{ }words\text{ }in\text{ }the\text{ }corpus}[/latex]
Generalizing above, the following can be said:
[latex]P(w_{i}) = \frac{c(w_{i})}{c(w)}[/latex]
In above formula, [latex]w_{i}[/latex] is any specific word, [latex]c(w_{i})[/latex] is count of specific word, and [latex]c(w)[/latex] is count of all words.
Scenario 2: The probability of a sequence of words is calculated based on the product of probabilities of words given occurrence of previous words. Let’s say, we need to calculate the probability of occurrence of the sentence, “best websites for comparing car insurances”. The probability of occurrence of this sentence will be calculated based on following formula:
[latex]P(“best\text{ }websites\text{ }for\text{ }comparing\text{ }car\text{ }insurance”) =[/latex]
[latex]P(best/startOfSentence)P(websites/best)P(for/websites)…P(endOfSentence/insurance)[/latex]
In above formula, the probability of a word given the previous word can be calculated using the formula such as following:
[latex]P(websites/best) = \frac{P(best\text{ }websites)}{P(best)}[/latex]
Generalizing above, the following can be said:
[latex]P(\frac{w_{i}}{w_{i-1}}) = \frac{P(w_{i-1}w_{i})}{P(w_{i-1})}[/latex]
N-Grams Language models
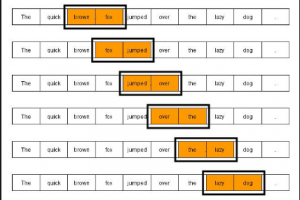
As defined earlier, Language models are used to determine the probability of a sequence of words. The sequence of words can be 2 words, 3 words, 4 words…n-words etc. N-grams is also termed as a sequence of n words. The language model which is based on determining probability based on the count of the sequence of words can be called as N-gram language model. Based on the count of words, N-gram can be:
- Unigram: Sequence of just 1 word
- Bigram: Sequence of 2 words
- Trigram: Sequence of 3 words
- …so on and so forth
Unigram Language Model Example
Let’s say we want to determine the probability of the sentence, “Which is the best car insurance package”. Based on Unigram language model, probability can be calculated as following:
[latex]P(“Which\text{ }is\text{ }best\text{ }car\text{ }insurance\text{ }package”) =[/latex]
[latex]P(which)P(is)…P(insurance)P(package)[/latex]
Above represents product of probability of occurrence of each of the words in the corpus. The probability of any word, [latex]w_{i}[/latex] can be calcuted as following:
[latex]P(w_{i}) = \frac{c(w_{i})}{c(w)}[/latex]
where [latex]w_{i}[/latex] is ith word, [latex]c(w_{i})[/latex] is count of [latex]w_{i}[/latex] in the corpus, and [latex]c(w)[/latex] is count of all the words.
Bigram Language Model Example
Using above sentence as example and Bigram language model, the probability can be determined as following:
[latex]P(“Which\text{ }is\text{ }best\text{ }car\text{ }insurance\text{ }package”) = [/latex]
[latex]P(\frac{which}{startOfSentence})P(\frac{is}{which})P(\frac{best}{is})..P(\frac{endOfSentence}{package})[/latex]
The following represents example of how to calculate each of the probabilities:
[latex]P(\frac{car}{best}) = \frac{P(best\text{ }car)}{P(best)}[/latex]
The above can also be calculated as following:
[latex]P(\frac{car}{best}) =[/latex]
[latex]\frac{c(best\text{ }car)}{c(best)}[/latex]
The above could be read as: Probability of word “car” given word “best” has occurred is probability of word “best car” divided by probability of word “best”. Alternatively, Probability of word “car” given word “best” has occurred is count of word “best car” divided by count of word “best”.
Above represents product of probability of occurrence of each of the word given earlier/previous word. Generally speaking, the probability of any word given previous word, [latex]\frac{w_{i}}{w_{i-1}}[/latex] can be calculated as following:
[latex]P(\frac{w_{i}}{w_{i-1}}) = \frac{P(w_{i-1},w_{i})}{P(w_{i-1})}[/latex]
Trigram Language Model Example
Let’s say we want to determine probability of the sentence, “Which company provides best car insurance package”. Using trigram language model, the probability can be determined as following:
[latex]P(“Which\text{ }company\text{ }provides\text{ }best\text{ }car\text{ }insurance\text{ }package”) = [/latex]
[latex]P(\frac{company}{which\text{ }startOfSentence})P(\frac{provides}{which\text{ }company})P(\frac{best}{company\text{ }provides})…P(\frac{endOfSentence}{insurance\text{ }package})[/latex]
The following represents example of how to calculate each of the probabilities:
[latex]P(\frac{provides}{which\text{ }company}) =[/latex]
[latex]\frac{P(which\text{ }company\text{ }provides)}{P(which\text{ }company)}[/latex]
The above can also be calculated as following:
[latex]P(\frac{provides}{which\text{ }company}) = [/latex]
[latex]\frac{c(which\text{ }company\text{ }provides)}{c(which\text{ }company)}[/latex]
The above could be read as: Probability of word “provides” given words “which company” has occurred is probability of word “which company provides” divided by probability of word “which company”. Alternatively, Probability of word “provides” given words “which company” has occurred is count of word “which company provides” divided by count of word “which company”.
Generalizing above, the probability of any word given two previous words, [latex]\frac{w_{i}}{w_{i-2},w_{i-1}}[/latex] can be calculated as following:
[latex]P(\frac{w_{i}}{w_{i-2},w_{i-1}}) = \frac{P(w_{i-2},w_{i-1},w_{i})}{P(w_{i-2},w_{i-1})}[/latex]
Further Reading
Summary
In this post, you learned about different types of N-grams language models and also saw examples.
Did you find this article useful? Do you have any questions or suggestions about this article or understanding N-grams language models? Leave a comment and ask your questions and I shall do my best to address your queries.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me