Have you been looking out for project folder structure or template for storing artifacts of your data science or machine learning project? Once there are teams working on a particular data science project and there arises a need for governance and automation of different aspects of the project using build automation tool such as Jenkins, one would feel the need to store the artifacts in well-structured project folders. In this post, you will learn about the folder structure using which you could choose to store your files/artifacts of your data science projects.
Folder Structure of Data Science Project
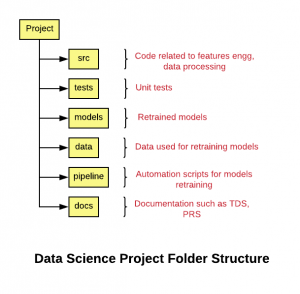
The following represents the folder structure for your data sciences project.
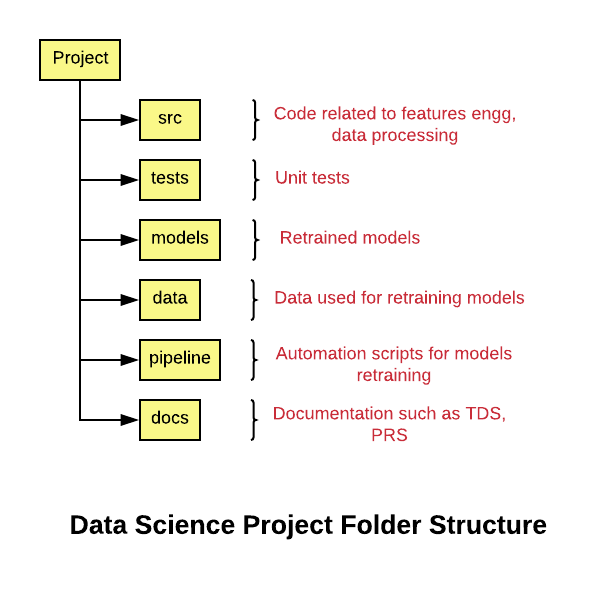
Fig 1. Data Science Project Folder Structure
Note that the project structure is created keeping in mind integration with build and automation jobs.
- project_name/
- src/
- tests/
- models/
- data/
- pipeline/
- docs/
- Readme.md
- …
If you are building machine learning models across different product lines, here could be the folder structure:
- product_name_1
- project_name_1
- src/
- tests/
- models
- data/
- pipeline/
- docs/
- Readme.md
- …
- project_name_2
- …
- project_name_1
- product_name_2
- …
The following are the details of the above-mentioned folder structure:
- project_name: Name of the project
- src: The folder consists of source code related to data gathering, data preparation, feature extraction etc
- tests: The folder consists of the code representing unit tests for code maintained with src folder.
- models: The folder consists of files representing trained/retrained models as part of build jobs or otherwise. The model names can be appropriately set as projectname_date_time or project_build_id (in case the model is created as part of build jobs). Another approach is to store the model files in a separate storage such as AWS S3, Google cloud storage or any other form of storage.
- data: The folder consists of data used for model training/retraining. The data could as well be stored in a separate storage.
- pipeline: The folder consists of code used for retraining and testing the model in an automated manner. These could be docker containers related code, scripts, workflow related code etc.
- docs: The folder consists of code related product requirement specifications (PRS), technical design specifications (TDS) etc.
Summary
In this post, you learned about the folder structure of a data science/machine learning project. Primarily, you will need to have folders for storing code for data/feature processing, tests, models, pipeline and documents.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me