This article represents a list of key machine learning algorithms which are most widely used by data scientists while doing data analysis. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos.
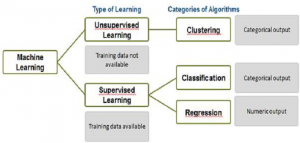
The list of machine learning algorithms presented below covers some of the most important and widely used algorithms which could set a stage for one to get started with data science/analytics and create models for predictions. Following are two high level classifications in which these machine learning algorithms fall under:
- Supervised learning
- Unsupervised learning
Following are some of the key tasks that are performed by machine learning algorithms falling under supervised and unsupervised learning:
- Classification: Place input data in a set of discreet categories. For example, whether an input data related cancerous cells represents benign or malignant cancer, or whether a hockey team will win or not, or whether a person will default on loan or not. Read further about classification on wikipedia page for classification
- Regression: Predict numeric value of target feature based on input values of other features. Read further details on wikipedia page for regression analysis
- Clustering: Divide input dataset into one or more homogenous groups. This is sometimes used for segmentation analysis which identifies groups of individuals with similar purchasing, donating, or demographic information such that promotion campaigns can be tailored to particular group of people. Read greater details about cluste analysis on wikipedia page
- Pattern Detection: Focuses on the recognition of patterns and regularities in data
Following is a list of algorithms listed under above categories:
- Supervised learning: Following algorithms can be used for performing classification and numerical value prediction tasks:
- Classification tasks:
- Nearest Neighbor
- naive Bayes
- Decision trees
- Classification rule learners
- Neural networks
- Support vector machine
- Numeric prediction tasks:
- Linear regression
- Regression trees
- Model trees
- Neural networks
- Support vector machine
- Classification tasks:
- Unsupervised learning: Following algorithms could be used for patterm detection and clustering tasks.
- Association rules (pattern detection)
- k-means clustering (clustering)

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning and BI. I would love to connect with you on Linkedin.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Latest posts by Ajitesh Kumar (see all)
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me