This blog represents my notes on how data is read and written from/to HDFS. Please feel free to suggest if it is done otherwise.
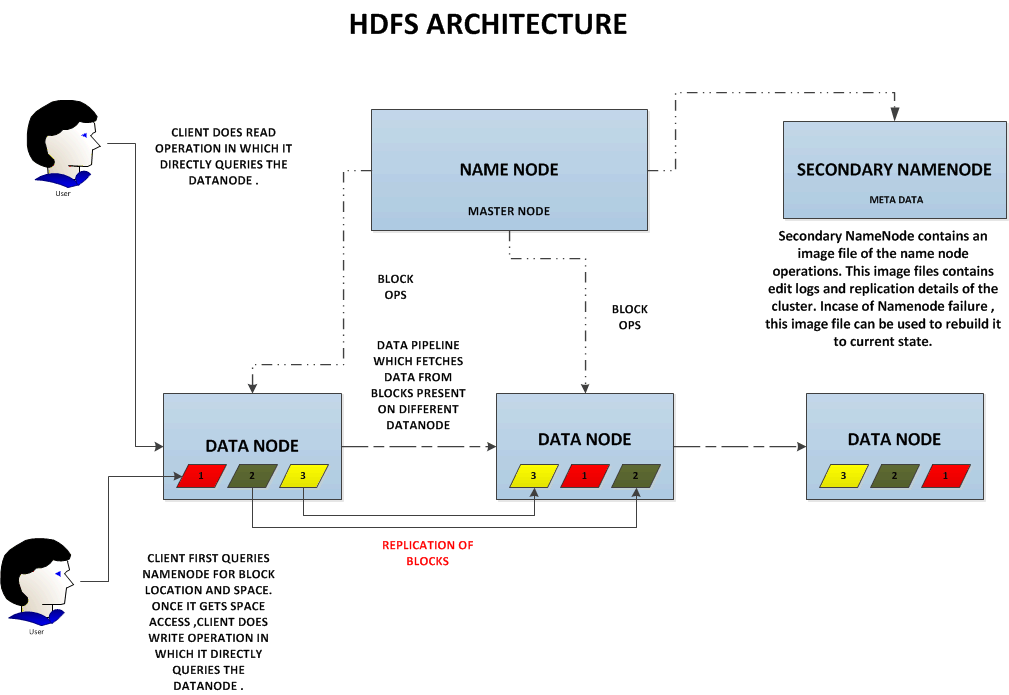
Following are steps using which clients retrieve data from HDFS:
- Clients ask Namenode for a file/data block
- Name-node returns data node information (ID) where the file/data blocks are located
- Client retrieves data directly from the data node.
Following are steps in which data is written to HDFS:
- Clients ask Name-node that they want to write one or more data blocks pertaining to a file.
- Name-node returns data nodes information to which these data blocks needs to be written
- Clients write each data block to the data nodes suggested.
- The data nodes then replicates the data block to other data nodes
- Informs Namenode about the write.
- Name-node commits EditLog
Following diagrams represents the data is read/written from/to HDFS.
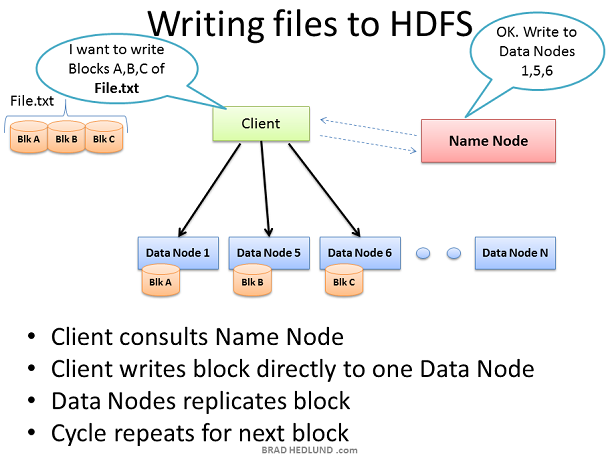
Following depicts how files are written to HDFS.

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning and BI. I would love to connect with you on Linkedin.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Check out my books titled as Designing Decisions, and First Principles Thinking.
Latest posts by Ajitesh Kumar (see all)
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me