
The article aims to describe how data is managed at LinkedIn.com, the most popular professional social networking site. Please shout out loud if you disagree with one or more of the aspects mentioned below. Also, do suggest if I missed on one or more aspects.
Data use-cases at LinkedIn.com
Following are some of the data use-cases that we may have come across while we are surfing various different LinkedIn pages:
- Update your profile, and the same appears in recruiter search in near real-time.
- Update your profile and same appears as network connections in near real-time.
- Share an update, and same appears on others news feed page in near real-time.
- Then, there are multiple read-only pages such as “People you may know”, “Viewer of your Profile”, “related searches” etc.
And, quite amazingly, the pages’ load time in all of the above use cases have been in milliseconds provided we have decent internet bandwidth. Kudos to LinkedIn Engineering team!
LinkedIn Data Architecture in Earlier Years
As like any other startups, LinkedIn in its early days lived on top a single RDBMS containing a handful of tables for user profiles and connections. Quite natural, isn’t it? This RDBMS was augmented by two additional database systems of which one was used to support full-text search for user-profile and other was used to support the social graph. These two DB system was kept up-to-date with the Databus, a change capture system whose primary goal is to capture the change in data set on the source-of-truth systems (such as Oracle) and update the same to additional DB systems.
However, it soon became a challenge to meet the website data needs with above data architecture, primarily, because of the need to achieve all of the below objectives which seemed to be not possible as per Brewer’s CAP theorem:
- Consistency (All applications see the same data at the same time)
- Availability (a guarantee that every request receives a response about whether it was successful or failed)
- Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
With above said, LinkedIn engineering team achieved what they called as timeline consistency (or eventual consistency with nearline systems explained below) along with other two characteristics such as availability and partition tolerance. Read further to see how LinkedIn data architecture looks today.
LinkedIn Data Architecture, Today
Given the need to support millions of users and related transactions to happen in fraction of seconds and not any more, the above data architecture was definitely not enough. Thus, LinkedIn engineering team came up with the three-phase data architecture consisting of online, offline and nearline data systems.At a high level, LinkedIn data are stored in following different forms of data systems (look at the diagram below):
- RDBMS
- Oracle
- MySQL (Used as underlying data store by Espresso)
- NoSQL
- Espresso (Home-grown document-oriented NoSQL data storage system)
- Voldemart (Key-value distributed storage system)
- HDFS (Stores the data of Hadoop map-reduce jobs)
- Caching
- Memcached
- Lucene-based Indexes
- Lucene indexes for storing data related with search, social graph etc.
- Also, used by Espresso
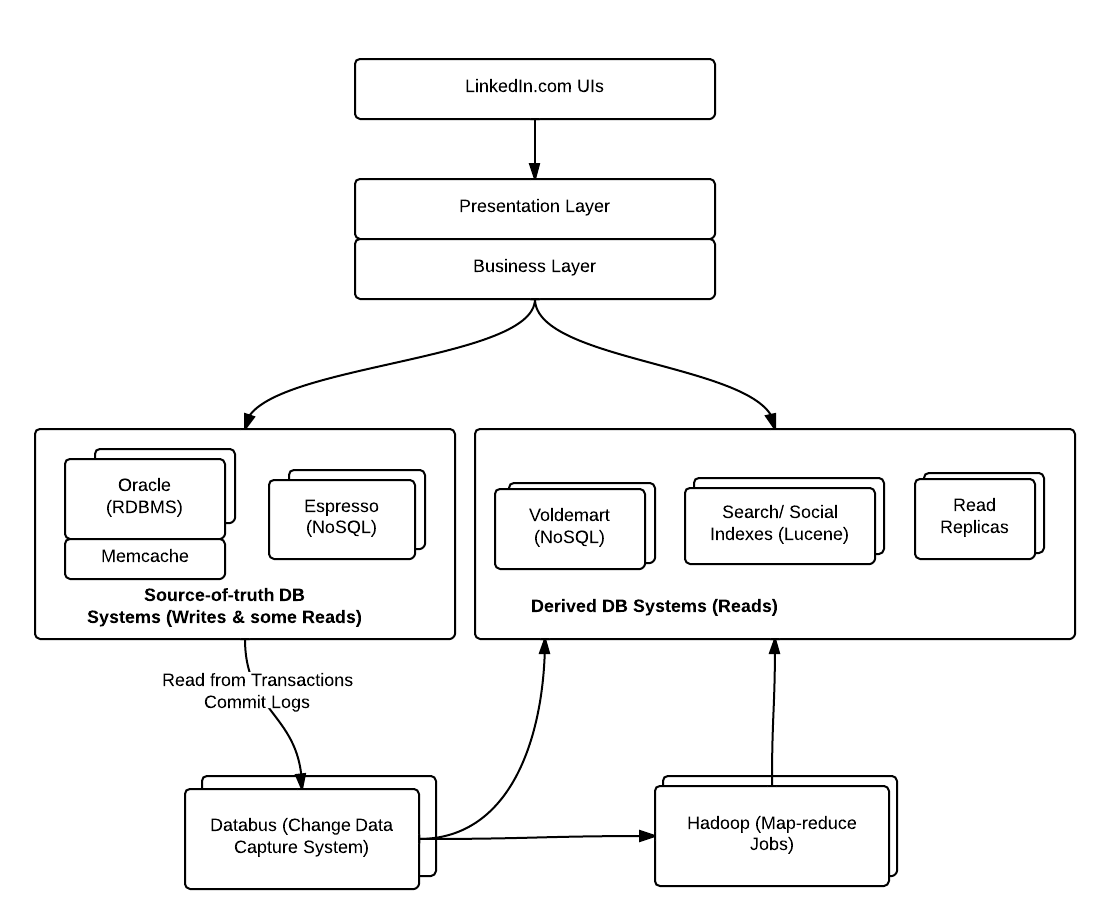
Fig: LinkedIn Database System representing DataBus, NoSQL, RDBMS, Indexes
Following is description of these three different systems in which above data stores can be categorized into:
Online DB Systems
The online systems handle users’ real-time interactions; Primary databases such as Oracle falls in this category. Primary data stores are used for users’ writes and only few reads. In case of Oracle, Writes are made on to Oracle master. Recently, LinkedIn has been working on yet another data system named as Espresso to fulfill the complex data needs which do not seem to be achieved by RDBMS such as Oracle. Lets keep a tab on whether they would be able to move entirely to NoSQL data storage system like Espresso and phase out Oracle completely or mostly.
Espresso is a horizontally scalable, indexed, timeline-consistent, document-oriented, highly available NoSQL data store. It is envisioned to replace legacy Oracle databases across the company’s web operations. It was originally designed to provide a usability boost for LinkedIn’s InMail messaging service. Currently, following are some of the applications that use Espresso as a source-of-truth system. That’s kind of amazing to see how NoSQL data store is used to handle so many application data needs.
- Member-member messages,
- Social gestures such as updates,
- Sharing articles
- Member profiles
- Company profiles
- News articles
Offline DB Systems
The offline systems, primarily Hadoop and a Teradata warehouse, handle batch processing and analytic workloads. The reason why it is called as offline is the batch handling of data. Apache Azkaban, is used for managing Hadoop & ETL jobs which extracts data from primary source-of-truth systems, runs map-reduce across it, stores the data in HDFS and notifies the consumers such as Voldemart to retrieve data appropriately. Consumers like Voldemart retrieves the data from HDFS and swap the indexes to keep the up-to-date data.
Nearline DB Systems (Timeline Consistency)
The nearline systems is created with aim to achieve timeline consistency (eventual consistency) and, handle features such as People You May Know (read-only data sets), search, social graph, which update constantly but require slightly less than online latency. Following are different types of nearline systems:
- Voldemart, Key-value storage DB, used to serve the read only pages. The data in Voldemart is fed using Hadoop framework( Hadoop Azkaban for scheduling Hadoop map-reduce jobs). These are nearline systems which gets data using offline systems such as Hadoop. Following are some of the pages which are fed data using Voldemart:
- People you may know
- Viewer of this profile also viewed
- Related searches
- Jobs you may be interested in
- Events you may be interested in
- Following are several different indexes which are updated using Databus, a change data capture system:
- People Search indexes which is used by Search-as-a-Service (SeaS). As you search the different people on LinkedIn, the data is derived from search indexes. This helps to a great deal to recruiters, in general.
- Social Graph indexes helps to display members/connections in one’s network. As a result ofthis, users start getting network updates almost immediately.
- Member profile data via Read replicas. These data are accessed by what is called standardization service. Read replicas are replicas of source database such that updates made to the source DB are copied to these read replica. The primary reason to have read replicas is to reduce the load on the source database (holding user-generated writes) by routing read queries to the read replica. Thus, any updates to LinkedIn member profile is not read from same database on which it got written. Rather, they are transferred to read-replicas.
Following represents how data change capture events are updated to nearline systems using databus:
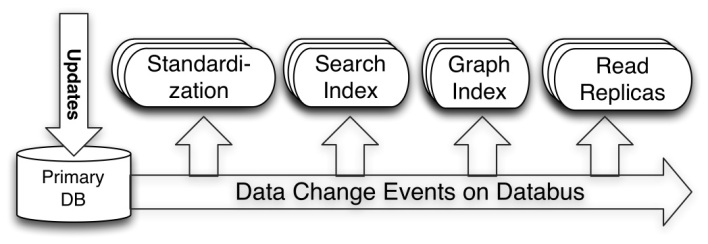
Data Use-case representing how it all comes together!
Let’s say you updated your profile with latest skills and position. You also accepts a connection request. What happens underneath:
- The write is updated in Oracle Master database
- Databus, then, does the magic by doing the following thereby achieving timeline consistency:
- Updates the profile change such as latest skills information and position change to standardization service
- Updates the profile change as mentioned above to search index service
- Updates the connection change to graph index service.
Data Architecture Lessons
Following are lessons that one could learn and apply in designing data architecture to achieve Data consistency, scalability and availability like that of LinkedIn.com:
- Different DB systems for writes & reads: One should plan to have two different kind of data systems, one for writes which can be be termed as “source-of-truth” systems and other, all kinds of users’ reads, that could be termed as derived DB systems. Thumb rule is to separate out databases for user-generated writes and users’ reads.
- Derived DB Systems: Users’ read should happen from derived DB systems or Read replicas. Derived DB systems could be created on top of some of the following:
- Lucene indexes
- NoSQL data stores such as Voldemart, Redis, Cassandra, MongoDB etc.
- For users’ reads, one could go out for creating indexes or key-value based data (from systems such as Hadoop map-reduce) from the primary source-of-truth DB systems and update these indexes/derived data (key-value) for every changes occurring as a result of user-generated writes on primary source-of-truth systems.
- One should choose between application-dual writes (writing primary DB and derived DB systems from applciation layer itself) or log mining (for reading transactions commit log from primary data stores using batch jobs) for keeping derived DB systems up-to-date.
- For creating derived data, one may plan to adopt Hadoop based map-reduce jobs which works on main or changed data sets, updates HDFS and notifies the derived data stores such as NoSQL stores such as Voldemart to retrieve the data.
- For data consistency, one may plan to create these data stores as distributed systems where each node in the cluster could again be created based on master-slave node. Each of these nodes could create horizontal data shards.
- For managing maximum uptime of these distributed data stores, one may plan to use cluster management tools such as Apache Helix etc.
References
- Siddarth Anand LinkedIn Data Infrastructure paper
- https://github.com/linkedin/databus
- http://gigaom.com/2013/03/03/how-and-why-linkedin-is-becoming-an-engineering-powerhouse/
- http://highscalability.com/blog/2012/3/19/linkedin-creating-a-low-latency-change-data-capture-system-w.html
[adsenseyu1]

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
shouldn’t the arrow btwn business layer and derived db systems (reads) be going the other way?
Thanks for the wonderful article explaining the architecture and data flow at a high level.
One question – for a near real time system – “where the reads are honored using Voldermot” – I am wondering when you mention that the input to the Voldermot system is from Batch processing systems.
If that is the case – how does it become a near real time system – since batch processing on platforms like Hadoop is inherently slow and time consuming.
Did I miss something ? Any clarification would be very appreciated ?
thanks
thanks for sharing! I can recognise similar principles as the ones in cqrs http://martinfowler.com/bliki/CQRS.html
I thought you guys replaced Databus with Kafka?