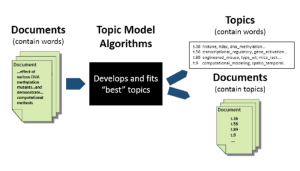
Are you overwhelmed by the endless streams of text data and looking for a way to unearth the hidden themes that lie within? Have you ever wondered how platforms like Google News manage to group similar articles together, or how businesses extract insights from vast volumes of customer reviews? The answer to these questions might be simpler than you think, and it’s rooted in the world of Topic Modeling.
Introducing Latent Dirichlet Allocation (LDA) – a powerful algorithm that offers a solution to the puzzle of understanding large text corpora. LDA is not just a buzzword in the data science community; it’s a mathematical tool that has found applications in various domains such as marketing, journalism, and academia.
In this blog post, we’ll demystify the LDA algorithm, explore its underlying mathematics, and delve into a hands-on Python example. Whether you’re a data scientist, a machine learning enthusiast, or simply curious about the world of natural language processing, this guide will equip you with the knowledge to implement Topic Modeling using LDA in Python.
What is Topic Modeling?
Topic modeling is a type of statistical modeling used to discover the abstract “topics” that occur in a collection of documents. It can be considered a form of text mining that organizes, understands, and summarizes large datasets. Topic modeling algorithms, like Latent Dirichlet Allocation (LDA), analyze the words within the documents and cluster them into specific topics. Each document is represented as a mixture of topics, and each topic is represented as a mixture of words.
With the exponential growth of textual data, manually categorizing and summarizing content becomes impossible. Topic modeling automates this process, allowing for efficient management of information. By summarizing customer feedback or market trends, businesses can make informed decisions, improve products, and enhance customer satisfaction. It enables personalized content delivery, enhancing user engagement and satisfaction.
In recent times, large language models (LLMs) are being leveraged for topic modeling as well. Models adopting LLMs include embedded topic models (ETM), contextualized topic models (CTM), BERTopic, etc.
- Embedded topic models combine the probabilistic topic modeling of LDA with the contextual information brought by word embeddings-most specifically, word2vec.
- Contextualized topic models are a family of topic models that use pre-trained representations of language (e.g., BERT) for topic modeling.
- BERTopic is a transformative approach in the realm of topic modeling, leveraging the contextual and semantic capabilities of BERT and employing c-TF-IDF to enhance the clustering and interpretability of topics. BERT (Bidirectional Encoder Representations from Transformers) is a transformer model that generates dense vector representations of text called embeddings. c-TF-IDF is a variation of the traditional TF-IDF method, emphasizing words that are specific to individual classes (or topics) within the document collection. It helps in identifying words that are not just frequent but also discriminative for the topics. c-TF-IDF is used to weigh the words within each topic, ensuring that the most relevant and distinctive words are emphasized in the topic description.
In this blog, we will have a quick overview of LDA and then look at Python code to implement topic modeling using LDA.
Implementing Topic Modeling using LDA: Python Example
Latent Dirichlet Allocation (LDA) algorithm is a generative probabilistic model designed to uncover the abstract “topics” within a corpus of documents. Topics are probability distributions over a fixed vocabulary of words. LDA assumes that each document in the corpus is composed of a mixture of various topics. Each topic is defined as a distribution of words, representing a specific theme or subject matter. Different topics may share common words, but with varying probabilities.
LDA employs the Dirichlet distribution as a prior to model the uncertainty about the proportion of topics in documents and the distribution of words in topics. It involves two hyperparameters, alpha and beta, which control the distribution of topics across documents and words across topics, respectively. Parameter alpha affects document-topic distribution and parameter beta affects topic word distribution. This is how the LDA algorithm works:
- Step 1: Initialization
- Choose the number of topics K you want to discover.
- Randomly assign topics to each word in the documents.
- Step 2: Iterative reassignment (Gibbs sampling)
- Iterate over each word in each document.
- For each word, compute the probabilities for all topics based on its current assignment and the assignments of other words.
- Reassign the word to a new topic based on these probabilities.
- Repeat until convergence, meaning the assignments become stable.
- Step 3: Building topics and document distributions
- Compute the distribution of topics for each document and the distribution of words for each topic. These distributions can also be termed as document-topic distribution and topic-word distribution respectively.
- These distributions form the final output, representing the hidden topics within the corpus.
LDA Python Example
Here is the python code example on how to implement topic modeling using LDA. The following scode represents tep-by-step method of topic modeling using the Latent Dirichlet Allocation (LDA) in Python, using the Gensim library. The following are key steps:
- Importing gensim and necessary libraries
- Defining the corpus and doing data preprocessing
- Creating dictionary and corpus required for LDA
- Building the LAD model
- Printing the topics
import gensim
from gensim import corpora
from nltk.corpus import stopwords
import nltk
# Download stopwords if needed
nltk.download('stopwords')
# Example corpus
documents = [
"Health experts recommend eating fruits and vegetables.",
"Exercise regularly to maintain a healthy body.",
"Technology is evolving rapidly with the advent of AI.",
"AI and machine learning are subfields of technology.",
"Eat well and exercise to stay healthy."
]
# Preprocess the documents
stop_words = set(stopwords.words('english'))
texts = [[word for word in document.lower().split() if word not in stop_words] for document in documents]
# Creating a term dictionary
dictionary = corpora.Dictionary(texts)
# Creating a document-term matrix
corpus = [dictionary.doc2bow(text) for text in texts]
# Create an LDA object
Lda = gensim.models.ldamodel.LdaModel
# Build the model
ldamodel = Lda(corpus, num_topics=2, id2word=dictionary, passes=15)
# Print the topics
topics = ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)
Conclusion
Topic modeling is used to find the abstract “topics” in a collection of documents. There are different algorithms used for topic modeling including the popular LDA algorithm and algorithms making use of large language models (BERTopic, contextual topic modeling, etc). LDA works by conceiving documents as mixtures of topics and topics as distributions of words. By building on fundamental principles like the Dirichlet distribution, it provides a robust and flexible framework for topic modeling.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me