Tag Archives: RAG
Chunking Strategies for RAG with Examples
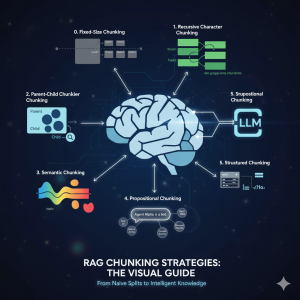
If you’ve built a “Naive” RAG pipeline, you’ve probably hit a wall. You’ve indexed your documents, but the answers are… mediocre. They’re out of context, they miss the point, or they just feel wrong. Here’s the truth: Your RAG system is only as good as its chunks. Chunking—the process of breaking your documents into searchable pieces—is one of the most important decision you will make in your RAG pipeline. It’s not just “preprocessing”; it is the foundation of your AI’s knowledge in the RAG application. The problem is what I call the “Chunking Goldilocks Problem”: Let’s walk through the evolution of chunking strategies, from the simple baseline to the state-of-the-art, …
Creating a RAG Application Using LangGraph: Example Code

Retrieval-Augmented Generation (RAG) is an innovative generative AI method that combines retrieval-based search with large language models (LLMs) to enhance response accuracy and contextual relevance. Unlike traditional retrieval systems that return existing documents or generative models that rely solely on pre-trained knowledge, RAG technique dynamically integrates context as retrieved information related to query with LLM outputs. LangGraph, an advanced extension of LangChain, provides a structured workflow for developing RAG applications. This guide will walk through the process of building a RAG system using LangGraph with example implementations. Setting Up the Environment To get started, we need to install the necessary dependencies. The following commands will ensure that all required LangChain …
Building a RAG Application with LangChain: Example Code

The combination of Retrieval-Augmented Generation (RAG) and powerful language models enables the development of sophisticated applications that leverage large datasets to answer questions effectively. In this blog, we will explore the steps to build an LLM RAG application using LangChain. Prerequisites Before diving into the implementation, ensure you have the required libraries installed. Execute the following command to install the necessary packages: Setting Up Environment Variables LangChain integrates with various APIs to enable tracing and embedding generation, which are crucial for debugging workflows and creating compact numerical representations of text data for efficient retrieval and processing in RAG applications. Set up the required environment variables for LangChain and OpenAI: Step …
How Indexing Works in LLM-Based RAG Applications
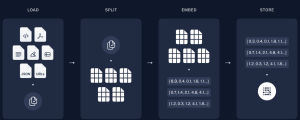
When building a Retrieval-Augmented Generation (RAG) application powered by Large Language Models (LLMs), which combine the ability to generate human-like text with advanced retrieval mechanisms for precise and contextually relevant information, effective indexing plays a pivotal role. It ensures that only the most contextually relevant data is retrieved and fed into the LLM, improving the quality and accuracy of the generated responses. This process reduces noise, optimizes token usage, and directly impacts the application’s ability to handle large datasets efficiently. RAG applications combine the generative capabilities of LLMs with information retrieval, making them ideal for tasks such as question-answering, summarization, or domain-specific problem-solving. This blog will walk you through the …

I found it very helpful. However the differences are not too understandable for me