With the increasing demand for more powerful machine learning (ML) systems that can handle diverse tasks, Mixture of Experts (MoE) models have emerged as a promising solution to scale large language models (LLM) without the prohibitive costs of computation. In this blog, we will delve into the concept of MoE, its history, challenges, and applications in modern transformer architectures, particularly focusing on the role of Google’s GShard and Switch Transformers.
What is a Mixture of Experts (MoE) Model?
Mixture of Experts (MoE) model represents a neural network architecture that divides a model into multiple sub-components (neural network) called experts. Each expert is designed to specialize in processing specific types of input data. The model also includes a router that directs each input to a subset of the available experts, rather than utilizing the entire model for every computation. The key feature of an MoE model is its sparsity—only a small number of experts are activated for any given input, making it more computationally efficient than traditional dense models.
Imagine that MoE is like having a team of specialists instead of generalists. When a problem arises, only the right specialists are called upon, allowing them to solve the problem effectively while using minimal resources. This mechanism allows MoE models to manage complex tasks and scale effectively.
The concept of MoE was introduced back in the 1990s as a way to improve model efficiency through the use of specialized components. However, the true potential of MoE was only realized in recent years with the emergence of large-scale computing and advancements in machine learning.
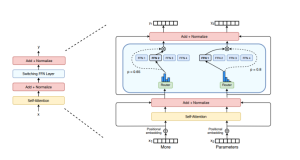
In 2021, Google introduced the Switch Transformer and GShard, which were among the first implementations of large-scale MoE architectures. Switch Transformers use a sparse MoE layer that significantly scales up the model while maintaining efficient resource usage. The following picture represents the same. Notice how multiple feed-forward networks (FFNs) are used in swtching FFN layer instead of a dense FFN. Also, note how a gated router is used to select an appropriate FFN for two different input tokens such as “More” and “Parameters”.
Google GShard is an implementation that uses Mixture of Experts (MoE) to scale transformer models effectively across multiple devices. GShard facilitates splitting the model into smaller parts (“shards“) and only activating a subset of experts for each input, which is a core principle of MoE. This allows GShard to achieve efficiency in computation and training by reducing resource usage while maintaining high performance on large-scale natural language processing tasks. It demonstrates how MoE principles can be practically applied to achieve significant scaling improvements in deep learning models.
How Does Mixture of Experts Work?
The core idea behind MoE is to replace some layers of a neural network with sparse layers consisting of multiple experts. These experts are only partially used at any given time, unlike in a dense model where all parameters are always active.
An MoE model consists of:
- Experts: Sub-models that perform specific computations, such as processing particular patterns of input data.
- Router: A component that determines which expert(s) to activate for each input. It learns a set of gating weights, which helps decide which experts are best suited to process the incoming data.
When an input is fed into an MoE model:
- The router evaluates the input and selects which experts will be used. This selection process allows for sparse activation—only a small subset of experts is activated per input.
- The selected experts independently process the input, and their outputs are aggregated to form the final output of the layer.
This selective activation means that while an MoE model may have many parameters, only a small number are used for each forward pass, making the model computationally efficient without sacrificing performance.
Advantages of MoE Models
The following are some of the key advantages of MoE models:
- Scalability: MoE models are highly scalable, allowing a large number of parameters to be added without a proportional increase in computational requirements. For instance, Google’s Switch Transformers leverage MoE to handle extremely large tasks that would otherwise be too resource-intensive for a dense model.
- Specialization: Different experts can be trained to specialize in different types of input, which leads to better performance. By dynamically selecting relevant experts, the model becomes more effective at handling a variety of tasks compared to a generalist model.
- Reduced Computation Cost: By activating only a subset of experts, the model’s computation during training and inference is significantly reduced. This allows the model to maintain a high level of performance while using fewer computational resources.
Inference and Memory Challenges
While MoE models excel in efficiency, they come with some challenges, particularly in inference and memory requirements.
- Inference Efficiency vs Memory Usage: During inference, only a few experts are activated for each input, which reduces the computational cost. However, all experts must be loaded into memory, meaning the memory requirement is high. For instance, in a model like Mixtral 8 x 7B, there are 8 experts with 7 billion parameters each. The model needs enough memory to hold all of these parameters, roughly equivalent to a dense 47B parameter model.
- Inference Speed: During inference, only a subset of the experts is activated (e.g., two experts), resulting in an inference cost comparable to a 12B parameter model. This is because the router only activates the most relevant experts, and the computation involves the parameters of these selected experts along with shared layers, thereby saving computation time compared to a dense model.
When to use MoE vs Dense Models?
Mixture of Experts (MoE) models are ideal when scalability and efficiency are needed, especially for handling large-scale datasets or complex tasks. MoE models activate only a subset of experts for each input, allowing for efficient use of computation and memory, which is beneficial for tasks that require specialization and have variable complexity.
Dense models, on the other hand, are preferable when consistent processing across all inputs is needed, such as smaller-scale applications or when specialized hardware and high memory availability are not present. Dense models are simpler to implement and can be more predictable in their computational requirements.
Conclusion
MoE models hold immense potential for the future of deep learning. Their ability to scale without linearly increasing computational resources makes them an attractive choice for developing even larger models capable of solving increasingly complex problems. While there are challenges associated with memory requirements and efficient routing, ongoing research continues to improve MoE models, making them more feasible and efficient.
As transformer models like Google’s Switch Transformer have demonstrated, incorporating sparsity via the MoE approach can lead to significant improvements in performance and efficiency. The goal is to strike the right balance between scalability, computational efficiency, and practical implementation challenges—something that MoE models are uniquely positioned to achieve.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me