Last updated: 3rd March, 2024
Understanding the difference between self-supervised learning and transfer learning, along with their practical applications, is crucial for any data scientist looking to optimize model performance and efficiency. Self-supervised learning and transfer learning are two pivotal techniques in machine learning, each with its unique approach to leveraging data for model training. Transfer learning capitalizes on a model pre-trained on a broad dataset with diverse categories, to serve as a foundational model for a more specialized task. his method relies on labeled data, often requiring significant human effort to label. Self-supervised learning, in contrast, pre-trains models using unlabeled data, creatively generating its labels from the inherent structure of the data. In this blog, we will look at the difference in visual representation.
What’s Transfer Learning?
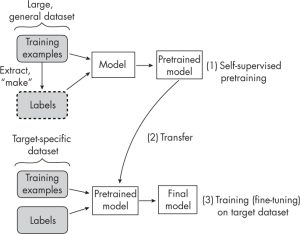
The following picture represents how transfer learning works. The first stage of transfer learning is creating a pre-trained model by training the model on a general dataset consisting of training examples and labels. The pre-trained model is then fed with target-specific dataset and labels and the training is done to come up with the final model which predicts relation to the target dataset.
What’s Self-supervised Learning?
Self-supervised learning can be understood as a pre-training procedure using which neural networks can use large unlabelled datasets for training in a supervised fashion. The following picture represents self-supervised learning. The key difference is that when creating a pre-trained model, the training is performed on an unlabelled dataset. An unlabeled dataset is considered for the training, and a way is found to obtain labels from the dataset’s structure to formulate a prediction task for the neural network, as shown in the picture below. Rest everything remains same.
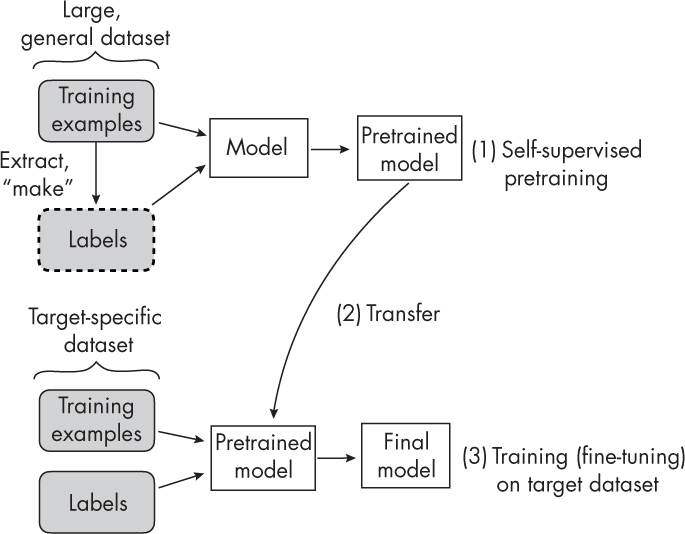
In transfer learning, the labels are provided along with the data set. In self-supervised learning, the labels are directly derived from the training examples.
An example of self-supervised learning tasks includes predicting the missing word in an NLP context. Alternatively, it can also predict the image patches in the image.
To learn more about the differences and greater details, check out this book – Machine Learning Q and AI by Sebastian Raschka.
Frequently Asked Questions (FAQs)
Q1. What is self-supervised learning, and when is it useful?
Self-supervised learning is a technique that leverages unlabeled data for training. It is particularly useful when working with large neural networks and when there’s a limited amount of labeled training data available. This approach allows for more efficient use of available data.
Q2: For which types of neural network architectures is self-supervised learning considered beneficial?
Self-supervised learning is especially beneficial for transformer-based architectures, such as those forming the basis of large language models (LLMs) and vision transformers. These architectures often require self-supervised learning for pretraining to enhance their performance. For small neural network models, like multilayer perceptrons with two or three layers, self-supervised learning is typically not considered useful or necessary.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me