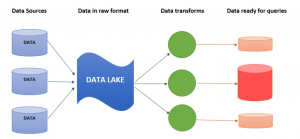
Data lakes are data storage systems that allow data to be stored, managed and accessed in a way that is cost-effective and scalable. They can provide a significant competitive advantage for any organization by enabling data-driven decision-making, but they also come with challenges in architecture design. In this blog post, we will explore the different components of data lakes, including the data lake architecture. Before getting to learn about data lake architectural component, lets quickly recall what is a data lake.
What is a data lake?
A data lake is a data storage system that allows data to be stored, managed, and accessed in a way that is cost-effective and scalable. Data lakes are also more flexible than data warehouses since there isn’t a specific structure that data must follow within the data lake; users can upload data into any location they choose and tag it with metadata.
Data lakes allow data scientists, analysts, or anyone else who needs to search for data within the data lake through searching metadata instead of going directly into the relational data warehouse. This speeds up the time needed to find information because users don’t need to know how data is organized within the data warehouse.
What are the different architectural components of a data lake?
The following represents different architectural components data lake:
- Datastore: Data is stored in data stores with different levels of granularity. The data can be accessed by applications through data services that use standardized interfaces to access data. Different types of data that can be stored in data lake include data in data warehouses, data from data marts, data from enterprise applications such as SAP systems, and data from less structured data sources such as text and XML. Datastore in a data lake can be of different types such as hot data store and cold data store. Cold data is stored in the data stores that have low velocity. These tend to be infrequently accessed datasets that are used for historical reporting purposes. This type of data may include things like year-on-year sales reports; this information typically isn’t used in data analysis. Hot data store, on the other hand, stores data that are accessed very frequently and tends to be used for real-time insights.
- Data catalog – Data lake will have a data catalog that provides metadata about data in the data store, which is used by the landing zone to provide data discovery and access capabilities for users. The data catalog provides data discovery and access capabilities to data scientists, business analysts, data engineers, and other users. It is integrated with data governance tools such as master data management (MDM) systems which store authoritative metadata about the organization’s critical entities including customers, products, and suppliers. Data catalogs can be used in conjunction with master data management (MDM) systems to track data lineage and own data quality.
- Data ETL pipelines: Data lake architecture will use data ETL pipelines to load data from existing data stores into the data store. This allows users to explore and access data from a variety of sources without moving it around or copying it, which can be very time-consuming and expensive. Data is transformed using ETL in the landing layer and moved to the data access layer from where it can be accessed by data scientists and other users for exploration and analysis purposes before being loaded into a data warehouse to enable structured querying. The transformation process includes the identification of required supporting attribute metadata to enable data discovery.
- Data ingestion pipelines: involves numerous steps in order to get data ready for analysis, including transformation, validation, and enrichment. Data ingestion challenges include data quality, data latency, and data volume. In order to ensure that data is reliable for analysis, data needs to be validated before being loaded into the landing zone in a data lake architecture.
- Data landing layer – Data lake architecture has a data landing zone, which is a layer that provides data management capabilities to prepare data for use by users. The goal of the data landing zone is to bring all data together, data from data warehouses as well as data from other sources.
- Data access layer: Data access layer provides a single point of entry into the lake where all users will go to discover, search and acquire data from data services that are exposed through the data access layer. Data access layer will provide a data access interface for users, which provides an API or web-based user interface that allows them to search and discover data in the data store through self-service means. This helps users find data without having to ask IT, staff, for help, which can be very time-consuming. In other words, data is democratized through the data access layer, which gives data scientists and other data users the ability to conduct ad hoc analyses without having to go through a formal process.
- Data processing environment – The data processing environment provides an execution context for interactive and batches analysis. It also manages workflows, which are used to orchestrate activities across data services. Data lake requires a data processing environment/context, which provides a data science workbench with the ability to process data from data services and applications where data is stored in a variety of formats.
- Data governance – Data lake’s data needs to be governed by a data steward, who is responsible for ensuring data quality and protecting it from unauthorized access or changes. Data stewards have the ability to define security policies that govern how data can be accessed in the data store, catalog, and landing zone by users with different roles. The architecture should also include data governance tools that can be used to review data lineage and data usage in real-time. This helps data stewards maintain control of the data, which is critical for compliance purposes but also provides valuable visibility into how different groups are using the information stored in the architecture.
- Data security – Data lakes require enterprise-class security features such as authentication, authorization, auditing, and encryption of data at rest and in data motion. Data security has become one of the most important (and often overlooked) data governance requirements for data lake adoption. It is required to protect data throughout its lifecycle, which includes data ingestion and preparation for analysis. Data security also enables compliance with regulatory requirements such as HIPAA (Health Insurance Portability and Accountability Act of 1996), SOC II (Statement on Standards No. 200), ISO 27001:2005, FISMA (Federal Information Security Management Act of 2002).
- Data lineage: Data lake architecture should include data lineage tools that can be used to monitor data movement within the architecture, which is critical for data governance purposes. Data lineage provides insight into how data is accessed or moved throughout different parts of the architecture so it can be reviewed in case there are any issues with data quality.
- Data masking: Data masking can be used in data lake architecture to ensure sensitive information remains private when copies of data are shared with data scientists or data analysts. Data masking can be achieved through data masking tools, which are used to automatically generate masks for data elements based on column values. Data masking provides data security by concealing or obfuscating data so that it cannot be read or interpreted until the right access controls have been applied to the masked data
- Meta-data registry: Meta-data registry stores metadata about data services, catalog data models, and data definitions. The metadata registry helps ensure the consistency of metadata by providing a single integration point for all data service layers within the architecture. Data lake requires a meta-data registry to help data stewards define data services and metadata, which will be used by data scientists in the data science layer.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me