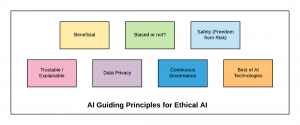
Is your organization using AI/machine learning for many of its products or planning to use AI models extensively for upcoming products? Do you have an AI guiding principles in place for stakeholders such as product management, data scientists/machine learning researchers to make sure that safe and unbiased AI (as appropriate) is used for developing AI-based solutions? Are you planning to create AI guiding principles for the AI stakeholders including business stakeholders, customers, partners etc?
If the answer to above is not in affirmation, it is recommended that you should start thinking about laying down AI guiding principles, sooner than later, in place to help different stakeholders such as executive team, product management, and data scientists to plan, build, test, deploy and govern AI-based products? The rapidly growing capabilities of AI-based systems has started inviting questions from business stakeholders including customers and partners to provide details on the impact, governance, ethics, and accountability of AI-based products made part of different business processes/workflows. No longer could a company afford to hide some of the above details in lights of IP-related or privacy concerns. In order to
In this post, you will learn about some of the AI guiding principles that you could set for your business. These guiding principles have been created based on the Google AI principles set by them for developing AI-based products. The following is the list of these AI principles:
- Overall beneficial to the business
- Avoiding unfair bias against a group of user entities
- Ensures safety of customer (Freedom from Business risks)
- Trustworthy – Customers can ask for an explanation
- Customer data privacy
- Continuous governance
- Built using best of AI tools & frameworks
The following diagram represents the AI guiding principles for Ethical AI:
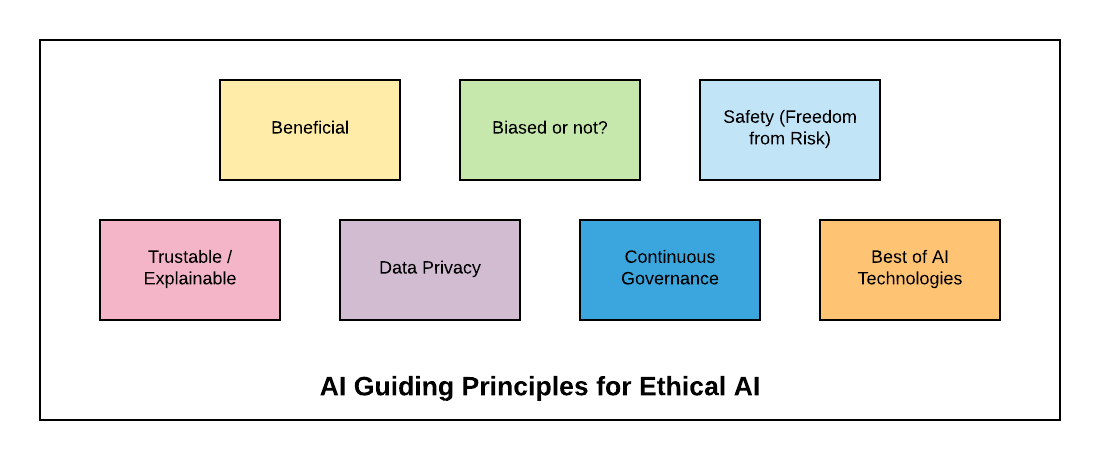
Fig: AI Guiding Principles for Ethical AI
Overall Beneficial to the Business (Beneficial)
AI/Machine learning models should be built to solve the complex business problems while ensuring that the models’ benefits outweigh the risks posed by the models. The following represents the examples of the different types of risks posed by the respective models:
- Fake news model: The model predicts whether a news is a fake news or not. The model has a high precision of 95% and a recall of 85%. The recall being 85% represents the fact that there is a set of news (although smaller in number) which fails to be predicted as fake and thus, filtered by the model. However, out of all news which got predicted as fake, 95% accuracy represents the fact that model does a good job of predicting a news as fake news. The model benefits, IMO, outweigh the harm done by false negatives.
- Cancer prediction model: Let’s say a model is built for predicting cancer. The precision of the model comes out to be 90% which reflects that of all predictions made by the model, 90% prediction is correct. So far so good. However, the recall value is 90%. This represents the fact that out of those who are actually suffering from Cancer, the model was able to correctly predict for 90% of people. Others got predicted as the false negative. Is that acceptable? I do not think so. Thus, this model won’t be accepted as it may end up hurting more than benefits.
Avoiding Unfair Bias to a Group of User Entities (Biased or not?)
AI/ML models often get trained with data sets with the underlying assumption or ignorance that the data set selected is unbiased. However, the reality is something different. While building models, both, the feature set and data associated with these features need to be checked for bias. The bias would need to be tested during both:
- During the model training phase
- Once the model is built and ready to be tested for moving it into production.
Let’s take a few examples to understand the bias in training datasets:
- Bias in image identification model: Let’s say there is a model built to identify the human beings in a given image. The discriminatory bias could get introduced into the model if the model is trained with images having people of white skin color. Thus, the model when tested with images having people of different skin color would not be able to classify the human beings in the correct manner.
- Bias in Hiring Model: Models built for Hiring could be subjected to bias such as hiring men or female for specific roles, or hiring those with white-sounding names, or hiring those with specific skill sets for specific positions.
- Bias in criminal prediction model: One could see bias in criminal prediction model when a person with black color skin is considered to have the higher likelihood of doing a crime once he has already committed a crime than the person with white skin color. The evaluation metrics shown below represents almost 45% false positives
One must understand that there are two different kinds of bias based on whether the bias is based on experience or discrimination. A doctor could use his experience to classify the patient as suffering from the disease or otherwise. This can be called as good bias. Alternatively, a model which fails to recognize the people of different skin color other than white is said to be discriminating in nature. This could be called as bad bias. The goal is to detect bad bias and eliminate them, either during model training phase or after the model is built.
Ensures Customer Safety (Freedom from Business Risks)
Models performance should be examined to minimize false positive/negatives appropriately to ensure freedom from the risk associated with business functions. Let’s take an example of a machine learning model (in account receivable domain) which predicts whether the buyers’ orders can be delivered based on his credit score. If the model incorrectly predicts that the order should be delivered as receivables, the supplier could be at risk of not receiving invoice payments on time which would further impact his revenue collections. Thus, such models should not be moved into production primarily due to the reason that it could impact business in the negative manner leading to the loss of revenue.
Trustable / Explainable – Customers can ask for Explanation
Models should be trustworthy/trustable or explainable. In this relation, the customers using the model prediction could ask for details related to which all features contributed to the prediction. Keeping this in mind, one should either be able to explain or derive at how the prediction was made or avoid using blackbox models where it gets difficult to explain the predictions and instead use simpler linear models.
Customer Data Privacy
As part of governance practice, customer data privacy should be respected. If customers are told/informed that their data privacy will be maintained and that their data won’t be used for any business-related purpose without informing them and taking their permissions, the same should be respected and governed as part of ML model review practices. Business should set up the QA team or audit team which makes sure that customer data privacy agreement is always respected.
Continuous Governance
Machine learning model life-cycle includes aspects related to some of the following:
- Data
- Feature engineering
- Models building (training/testing)
- ML pipeline / infrastructure
As part of AI guiding principles, the continuous governance controls should be put to audit aspects related to all of the above. The following represents some of the governance controls:
- Data: Whether the model is trained with adversary data set needs to be checked in a continuous manner in either manual or automated ways. Secondly, whether data which is not allowed to be used for building the model is used otherwise.
- Feature Engineering: Whether features importance has been checked or not. Whether derived features ended up using data which is not allowed as per the data privacy agreement. Whether unit tests have been written for feature generation code.
- Models building: Whether the model performance is optimum. Whether the model is tested for bias. Whether the model is tested on different slices of data.
- ML pipeline: Whether ML pipeline is secured or not.
Best of AI Tools & Frameworks
It must be ensured that AI models should be built using the best of tools and frameworks. In addition, it must also be governed that people involved in building AI models are trained appropriately at regular intervals with best practices and up-to-date educational materials. The tools and frameworks must ensure some of the following:
- Most advanced AI technologies such as AutoML, Bias tools are used.
- Best practices related to safety is adopted.
References
Summary
In this post, you learned about the AI guiding principles which you would want to consider setting for your AI/ML team and business stakeholders including executive management, customers and partners for developing and governing AI-based solutions. Some of the most important AI guiding principles include safety, bias and trust-ability / explain-ability.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me