Have you ever needed to extract text from an image or a PDF file? If so, you’re in luck! Python has an amazing library called Tesseract that can perform Optical Character Recognition (OCR) to extract text from images and PDFs. In this blog, I will share sample Python code using with you can use Tesseract to extract text from images and PDFs. As a data scientist, it can be very helpful and useful to be able to extract text from images or PDFs, especially when working with large amounts of data found in receipts, invoices, etc.
Tesseract is an OCR engine widely used in the industry, known for its accuracy and speed in extracting text from images and PDFs. It was initially developed by HP in the 1980s and later taken over by Google. Tesseract’s real-world usage is extensive, ranging from digitizing historical documents, extracting text from receipts, invoices, and forms, to improving accessibility for visually impaired individuals. Tesseract’s versatility and power make it an essential tool for data scientists, opening up new possibilities for data analysis and machine learning.
Python Tesseract OCR (Image-to-Text) Example
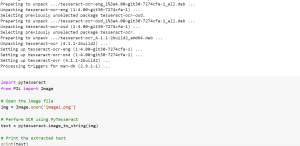
Let’s start with an example of how to extract text from an image using Tesseract. First, we’ll need to install Tesseract and its Python wrapper, PyTesseract. You might also need to install packages such as pdf2image, popper-utils, tesseract-ocr. Note that pdf2image is needed for PDF-to-Text conversion.
You can do this by running the following command:
!pip install pytesseract
!pip install pdf2image
!apt-get install poppler-utils
!apt-get install tesseract-ocr
Once installed, we’ll import the required libraries and use the following code to perform OCR:
import pytesseract
from PIL import Image
# Open the image file
img = Image.open('image1.png')
# Perform OCR using PyTesseract
text = pytesseract.image_to_string(img)
# Print the extracted text
print(text)
That’s it! With just a few lines of code, we were able to extract text from an image using Tesseract.
Python Tesseract PDF-to-Text Example
Now let’s move on to extracting text from a PDF file. The following code can be used to convert PDF file to text file.
import io
import pytesseract
from pdf2image import convert_from_path
def extract_text_from_pdf(pdf_path):
# Convert PDF to image
pages = convert_from_path(pdf_path, 500)
# Extract text from each page using Tesseract OCR
text_data = ''
for page in pages:
text = pytesseract.image_to_string(page)
text_data += text + '\n'
# Return the text data
return text_data
text = extract_text_from_pdf('Pfizer_Performance_Annual_Review.pdf')
print(text)
In the above code, we first convert the PDF file to a sequence of images using pdf2image. Then, we used PyTesseract to perform OCR on each image and extracted the text. In the end, all of the extracted text was concatenated and returned as a single string.
Conclusion
Tesseract is a powerful tool that can be used to extract text from images and PDFs in Python. We saw how to use PyTesseract to perform OCR on an image and extract text from it. We also learned how to use pdf2image to convert a PDF file to a sequence of images and then use PyTesseract to extract text from each image. These techniques can be very useful for data scientists working with large amounts of data, especially when dealing with unstructured data. With just a few lines of code, you can easily extract text from images and PDFs, opening up new possibilities for data analysis and machine learning.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025
- RAG Pipeline: 6 Steps for Creating Naive RAG App - November 1, 2025
I found it very helpful. However the differences are not too understandable for me