Fig 2. Multiple linear regression
Last updated: 15th Dec, 2023
In this post, the linear regression concepts in machine learning is explained with multiple real-life examples. Two types of regression models (simple/univariate and multiple/multivariate linear regression) are taken up for sighting examples. In addition, Python code examples are used for demonstrating training of simple linear and multiple linear regression models. In case you are a machine learning or data science beginner, you may find this post helpful enough. You may also want to check a detailed post – What is Machine Learning? Concepts & Examples.
Linear regression is a machine learning concept that is used to build or train the models for solving supervised learning problems related to predicting continuous numerical value. Recall that the supervised learning problems represent the class of the problems where the value (data) of the independent or predictor variable (features) and the dependent or response variables are already known. The known values of the dependent and independent variables are used to come up with a mathematical model also called as linear regression equation which is later used to make the predictions.
The following is an example of simple linear or univariate linear regression analysis representing the relationship between the height and weight in adults using the regression line. The regression line is superimposed over the scatterplot of height vs weight to showcase the linear relationship.
Building linear regression models represents determining the value of output (dependent/response variable) as a function of the weighted sum of coefficients and input features (independent / predictor variables) while making use of historical dataset This data is used to determine the most optimum value of the coefficients of the independent variables.
Here are few assumptions which need to be kept in mind when building linear regression models:
Let’s say, there is a numerical response variable, Y, and one or more predictor variables X1, X2, etc. Let’s say, hypothetically speaking, the following represents the relationship between Y and X in the real world.
$\Large Y_i = f(X) + error$
Where $Y_i$ is the actual or observed value and f is some fixed but unknown function of X1 and X2. We need to find this function based on training the model that would estimate or predict some value, $\hat{Y_i}$. The difference between the actual or observed value, $Y_i$ and the predicted value, $\hat{Y_i}$ is called as the error or residual. When the unknown function is a linear function of X1 and X2, the Y becomes a linear regression function or model such as the following. Note that the error term averages out to be zero.
$\Large \hat{Y_i} = b_0 + b_1*X_1 + b_2*X_2$
In the above equation, different values of Y and X1, and X2 are known during the model training phase. As part of training the model, the most optimal value of coefficients b1, b2, and b0 are determined based on the least square regression algorithm. The least-squares method algorithm is used to find the best fit for a set of data points by minimizing the sum of the squared residuals or square of error of points (actual values representing the response variable) from the points on the plotted curve (predicted value). This is shown below.
If $Y_i$ is the ith observed value and $\hat{Y_i}$ is the ith predicted value, then the ith residual or error value is calculated as the following:
$\Large e_i = Y_i – \hat{Y_i} $
The residual sum of squares can then be calculated as the following:
$\Large RSS = {e_1}^2 + {e_2}^2 + {e_3}^2 + … + {e_n}^2$
In order to come up with the optimal linear regression model, the least-squares method as discussed above represents minimizing the value of RSS (Residual sum of squares).
In order to select the most appropriate variables / features such as X1, X2, etc., the hypothesis is laid down around the coefficient for each of the variables / features. The null hypothesis is that the value of coefficients are 0. This means that the value of b0, b1, b2, etc. are 0. The alternate hypothesis is that the coefficients are not equal to zero. In this manner, the dependent variable holds good. T-statistics is used for hypothesis testing and reject the null hypothesis (b0, b1 or b2 = 0) if appropriate. The following is the formula of the t-statistics with n-2 degree of freedom. For more details, read my related blog – linear regression and t-test.
$\Large t = \frac{b_i}{StandardError(b_i)}$
There are two different types of linear regression models. They are the following:
Fig 1. Simple linear regression
The following mathematical formula represents the simple regression model:
$\Large Y_i = b*{X_i} + b_0 + error$
Fig 2. Multiple linear regression
The following formula can be used to represent a typical multiple regression model:
$\Large Y_i = b_0 + b_1*X_1 + b_2*X_2 + b_3*X_3 + … + b_n*X_n + error$
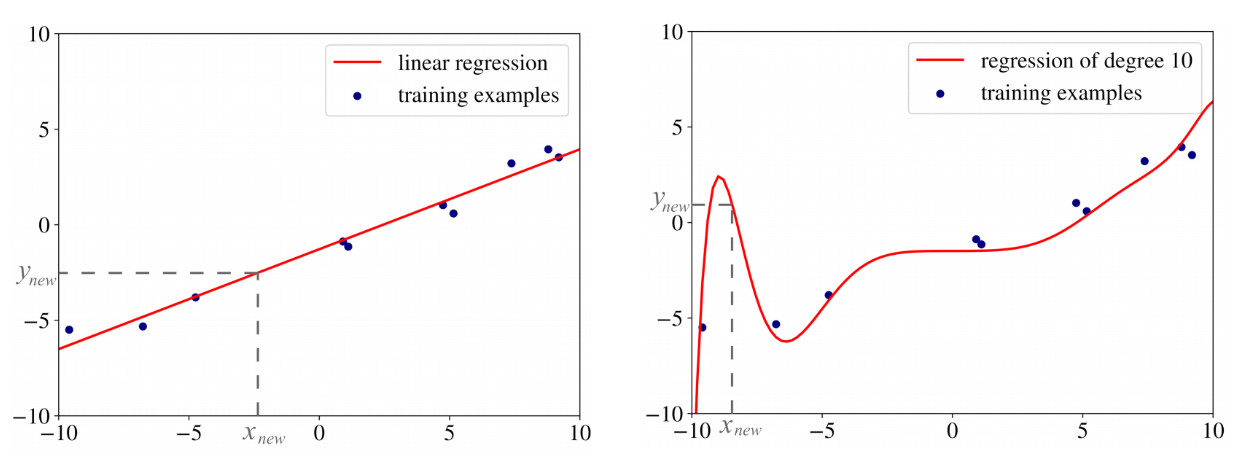
We have seen that the linear regression model is learned as the linear combination of features to predict the value of the target or response variable. However, we could use a square or some other polynomial to combine the values of features and predict the value of the target variable. This would turn out to be a more complex model than the linear one. One of the reasons why the linear regression model is more useful than the polynomial regression is the fact that the polynomial regression tends to overfit. The picture below represents the linear vs polynomial regression model and represents how the polynomial regression model tends to overfit.
Before looking into the Python implementation of simple linear regression machine learning model, let’s consider the problem of predicting the marks of a student based on the number of hours he/she put into the preparation. Although at the outset, it may look like a problem that can be modeled using simple linear regression, it could turn out to be a multiple linear regression problem depending on multiple input features. Alternatively, it may also turn out to be a non-linear problem. However, for the sake of example, let’s consider this as a simple linear regression problem.
However, let’s assume for the sake of understanding that the marks of a student (M) do depend on the number of hours (H) he/she put up for preparation. The following formula can represent the model:
Marks = function (No. of hours)
=> Marks = m*Hours + c
The best way to determine whether it is a simple linear regression problem is to do a plot of Marks vs Hours. If the plot comes like below, it may be inferred that a linear model can be used for this problem.
Fig 3. Plot representing a simple linear model for predicting marks
The data represented in the above plot would be used to find out a line such as the following which represents a best-fit line. The slope of the best-fit line would be the value of “m”.
Fig 4. Plot representing a simple linear model with a regression line
The value of m (slope of the line) can be determined using an objective function which is a combination of the loss or cost function and a regularization term. For simple linear regression, the objective function would be the summation of Mean Squared Error (MSE). MSE is the sum of squared distances between the target variable (actual marks) and the predicted values (marks calculated using the above equation). The best fit line would be obtained by minimizing the objective function (summation of mean squared error).
The following is the python code implementation of simple linear regression model for predicting marks based on the number of study hours. The Mean Squared Error (MSE) of the model on the test set is used to assess the performance of the regression model. This MSE value represents the average squared difference between the actual and predicted marks, indicating the accuracy of the model. A lower MSE value would suggest a more accurate model.
from sklearn.linear_model import LinearRegression
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Hypothetical data
np.random.seed(0)
hours = np.random.uniform(0, 10, 100) # Number of hours
marks = np.random.uniform(0, 100, 100) # Marks obtained
# Creating a DataFrame
data = pd.DataFrame({
'Hours': hours,
'Marks': marks
})
# Defining the independent variable (feature) and the dependent variable (target)
X = data[['Hours']]
y = data['Marks']
# Splitting the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creating the Linear Regression model
model = LinearRegression()
# Training the model
model.fit(X_train, y_train)
# Predicting on the test set
y_pred = model.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
# Coefficient (m) and Intercept (c)
m = model.coef_[0]
c = model.intercept_
m, c, mse
Before looking into the Python implementation of multiple linear regression, let’s look at a related problem of predicting weight reduction based on different parameters (hence, multiple regression). The problem of predicting weight reduction in form of the number of KGs reduced, hypothetically, could depend upon input features such as age, height, the weight of the person, and the time spent on exercises, .
Weight Reduction = Function(Age, Height, Weight, TimeOnExercise)
=> Shoe-size = b1*Height + b2*Weight + b3*age + b4*timeOnExercise + b0
As part of training the above model, the goal would be to find the value of b1, b2, b3, b4, and b0 which would minimize the objective function. The objective function would be the summation of mean squared error which is nothing but the sum of the square of the actual value and the predicted value for different values of age, height, weight, and timeOnExercise.
The following is the python code implementation of multiple linear regression machine learning model for predicting weight reduction based on age, height, weight, and time spent on exercises. As like simple linear regression model, the MSE of the model on the test set is used to assess the regression model performance.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Hypothetical data for demonstration purposes
# Let's create a dataset with 100 samples
np.random.seed(0)
age = np.random.randint(18, 65, 100)
height = np.random.uniform(1.5, 2.0, 100)
weight = np.random.uniform(50, 100, 100)
time_on_exercise = np.random.uniform(0.5, 2.5, 100)
weight_reduction = np.random.uniform(0, 10, 100) # This will be our target variable
# Creating a DataFrame
data = pd.DataFrame({
'Age': age,
'Height': height,
'Weight': weight,
'TimeOnExercise': time_on_exercise,
'WeightReduction': weight_reduction
})
# Defining the independent variables (features) and the dependent variable (target)
X = data[['Age', 'Height', 'Weight', 'TimeOnExercise']]
y = data['WeightReduction']
# Splitting the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creating the Linear Regression model
model = LinearRegression()
# Training the model
model.fit(X_train, y_train)
# Predicting on the test set
y_pred = model.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
# Coefficients (b1, b2, b3, b4) and Intercept (b0)
b1, b2, b3, b4 = model.coef_
b0 = model.intercept_
b1, b2, b3, b4, b0, mse
The following are some key terminologies in relation to measuring the residuals and performance of the linear regression machine learning models:
While working with linear regression models, some of the following assumptions are made about the data. If these assumptions are violated, the results of linear regression analysis might not turn out to be valid:
The following represents some real-world problems’ examples / use cases where linear regression machine learning models can be used:
The following is a list of FAQs related to linear regression algorithm / machine learning models.
Here are some of my other posts in relation to linear regression:
In this post, you learned about linear regression, different types of linear regression machine learning models, and examples for each one of them. It can be noted that a supervised learning problem where the output variable is linearly dependent on input features could be solved using linear regression models. Linear regression models get trained using a simple linear or multiple linear regression algorithm which represents the output variable as the summation of weighted input features.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
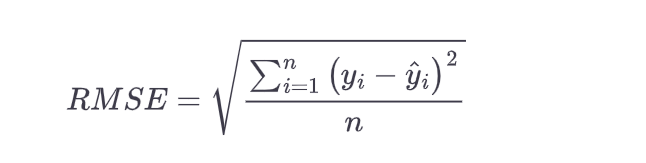{kind=link}
{kind=link}
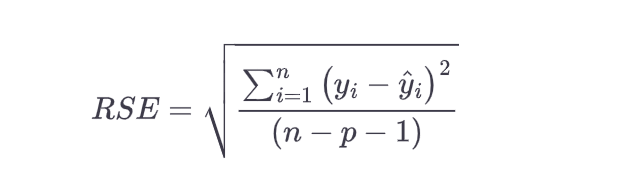{kind=link}
View Comments
how to cite this source? can you provide the hyperlink or source?
You can use this URL: https://vitalflux.com/linear-regression-real-life-example/
Thank you