Last updated: 21st Jan, 2024
Machine Learning (ML) models are designed to make predictions or decisions based on data. However, a common challenge, data scientists face when developing these models is ensuring that they generalize well to new, unseen data. Generalization refers to a model’s ability to perform accurately on new, unseen examples after being trained on a limited set of data. When models don’t generalize well, they commit errors. These errors are called generalization errors. In this blog, you will learn about different types of generalization errors, with examples, and walk through a simple Python demonstration to illustrate these concepts.
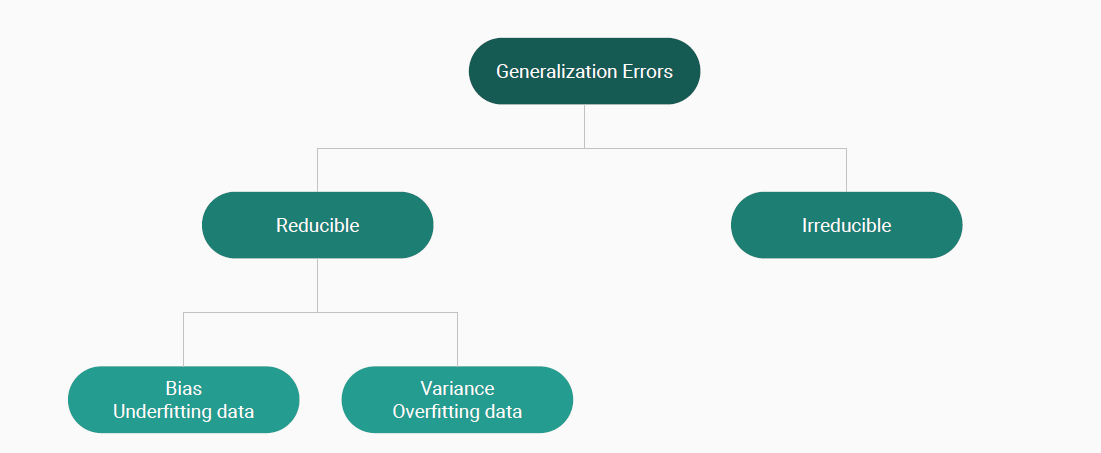
Generalization errors in machine learning / data science can be broadly divided into two categories: reducible and irreducible errors.
Reducible errors in machine learning are those parts of the prediction error that can be reduced or eliminated by improving the model. They consist of two main components: bias and variance. These errors are termed “reducible” because they are due to the model’s inability to capture the true relationship in the training data, and theoretically, they can be minimized with better model selection, more data, or improved training procedures.
Irreducible errors are those that cannot be reduced by any model due to the inherent noise or randomness in the data itself. No matter how sophisticated the model, there will always be some level of error due to factors we cannot predict or have not measured.
To demonstrate these concepts, let’s take up a data science problem of predicting house prices based on various features like size, location, number of rooms, age, etc. We will train a model using Python, calculate metrics to determine the generalization error, and identify the errors as bias or variance.
We will train two models: a simple linear regression model that may underfit and a complex decision tree that may overfit.
A linear regression model will be trying to predict housing prices regardless of features like location, number of rooms, or age of the house. This model assumes a simple relationship and would likely have high bias as it oversimplifies the problem.
A decision tree would tend to grow very deep such that it would learn the training data including the noise. This model will likely have high variance and perform poorly on unseen data because it’s too tailored to the specific examples in the training set.
Let’s look at the Python code with models trained on California housing dataset.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
X, y = housing.data, housing.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Linear Regression Model
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# Decision Tree Regressor
dt_model = DecisionTreeRegressor(max_depth=10)
dt_model.fit(X_train, y_train)
# MSE on training & test dataset for Linear Regression
y_train_pred_lr = lr_model.predict(X_train)
mse_train_lr = mean_squared_error(y_train, y_train_pred_lr)
y_pred_lr = lr_model.predict(X_test)
mse_lr = mean_squared_error(y_test, y_pred_lr)
# MSE on training and test dataset for Decision Tree
y_train_pred_dt = dt_model.predict(X_train)
mse_train_dt = mean_squared_error(y_train, y_train_pred_dt)
y_pred_dt = dt_model.predict(X_test)
mse_dt = mean_squared_error(y_test, y_pred_dt)
# Output the MSE values for training and test dataset for linear regression
print(f"Linear Regression Training MSE: {mse_train_lr}")
print(f"Linear Regression Test MSE: {mse_lr}")
# Output the MSE on the training and test dataset for decision tree model
print(f"Decision Tree Training MSE: {mse_train_dt}")
print(f"Decision Tree Test MSE: {mse_dt}")
The following gets printed as a result of executing the above code:
Linear Regression Training MSE: 0.5179331255246699
Linear Regression Test MSE: 0.5558915986952422
Decision Tree Training MSE: 0.2208657912045762
Decision Tree Test MSE: 0.42106415822823845
Let’s analyze and understand the reducible errors concept of bias and variance.
The output of the Mean Squared Error (MSE) for both the Linear Regression and the Decision Tree models on the training and test sets provides valuable insights into their performance and whether they suffer from high bias or high variance.
The MSE for the Linear Regression model on the training data and the test data are quite close to each other, and both are moderately high. This suggests that the model is consistent across both datasets, which is a good sign in terms of variance. However, since the error is not particularly low on either, it indicates that the model may not be complex enough to capture all the underlying relationships in the data. This is indicative of high bias. The model is underfitting the dataset, meaning that it is too simplistic and does not have enough capacity to learn the details and the complexity of the data.
The Decision Tree model’s MSE on the training data is significantly lower than its MSE on the test data. This large discrepancy suggests that while the Decision Tree model is able to fit the training data very well (potentially too well), it does not perform as well on the test data. This is a classic sign of high variance, which indicates that the model is overfitting the training data. It has learned the noise in the training set to the extent that it negatively impacts its performance on unseen data.
Now that we know how to determine whether the model is having which type of reducible generalization error such as bias or variance, lets learn how to address these generalization errors.
The following are some of the most common frequently asked questions related to generalization errors in machine learning:
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}