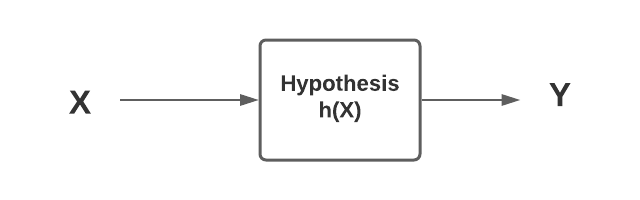
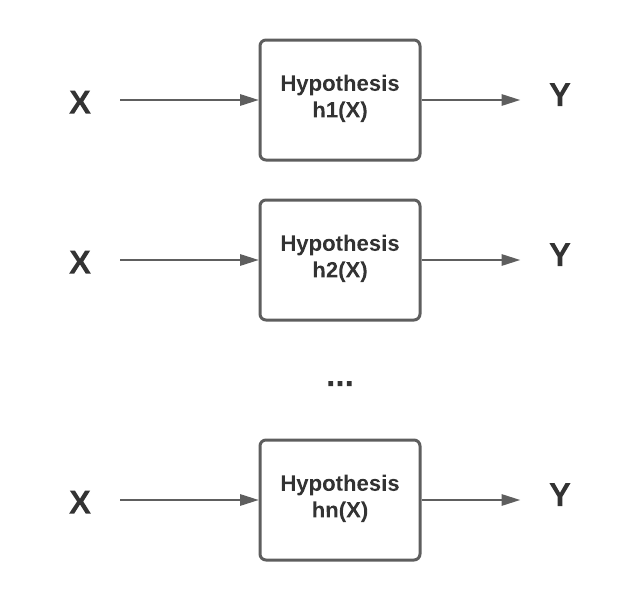
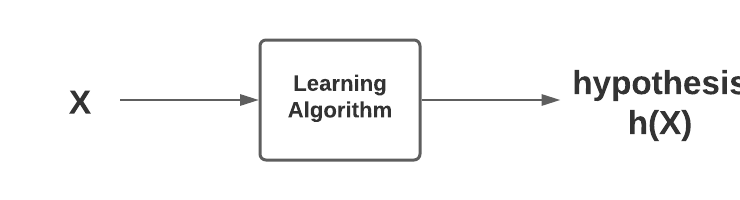
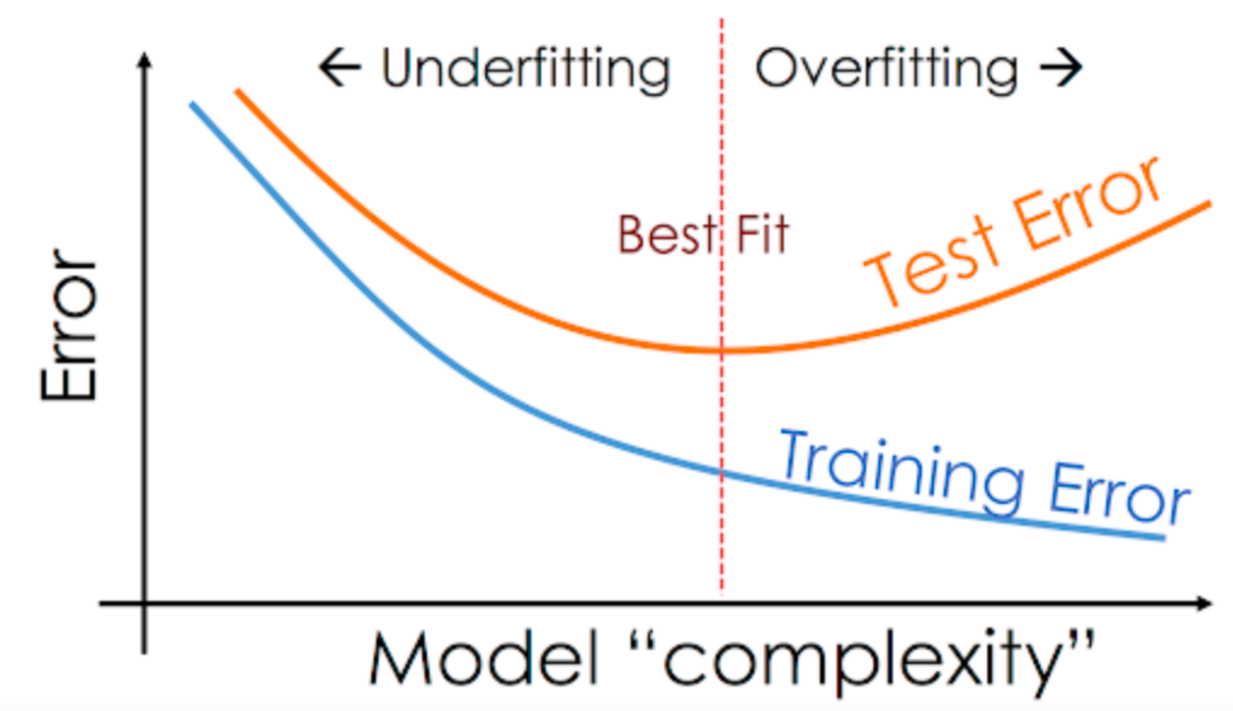
ML Terminologies Hypothesis Space
When starting on the journey of learning machine learning and data science, we come across several different terminologies when going through different articles/posts, books & video lectures. Getting a good understanding of these terminologies and related concepts will help us understand these concepts in a nice manner. At a senior level, it gets tricky at times when the team of data scientists / ML engineers explain their projects and related outcomes. With this in context, this post lists down a set of commonly used machine learning terminologies that will help us get a good understanding of ML concepts and also engage with the DS / AI / ML team in a nice manner.
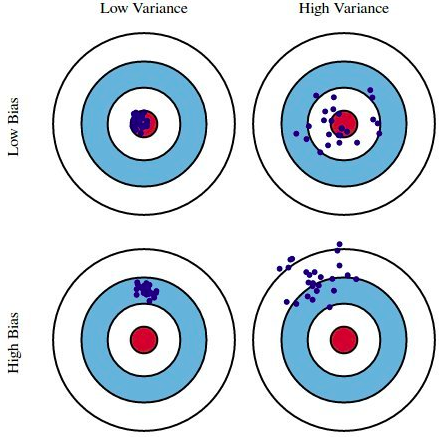
Here is a list of basic terminologies in machine learning & the related definitions:
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}