In the realm of predictive modeling and data science, regression analysis stands as a cornerstone technique. It’s essential for understanding relationships in data, forecasting trends, and making informed decisions. This guide delves into the nuances of Linear Regression and Polynomial Regression, two fundamental approaches, highlighting their practical applications with Python examples.
In this section, we will learn about what are linear and polynomial regression.
Linear Regression is a statistical method used in predictive analysis. It’s a straightforward approach for modeling the relationship between a dependent variable (often denoted as y) and one or more independent variables (denoted as x). In simple linear regression, there’s only one independent variable. The purpose of linear regression is to find a linear equation, y=mx+c (where m is the slope and c is the y-intercept or bias), that best fits the data. This model is extensively used in various fields like economics, biology, engineering, and more, primarily for forecasting, trend analysis, and determining causal relationships.
Expanding on this, we encounter Multiple Linear Regression, a variant that includes two or more independent variables. In this model, the equation takes the form $y = b_0 + b_1*x_1 + b_2*x_2 + … + b_n*x_n$ , where b0 is the intercept, and b1,b2,…,bn are coefficients representing the impact of each independent variable on the dependent variable. This form of regression is particularly useful in real-world scenarios where the dependent variable is influenced by multiple factors. For instance, in predicting housing prices, multiple linear regression can simultaneously account for variables like size, location, and the number of bedrooms.
The primary purpose of both simple and multiple linear regression is to find a linear function that best fits the given data.
Polynomial Regression, a more complex form of regression analysis, extends the linear model by adding extra predictors, obtained by raising each of the original predictors to a power. This model is represented as $y = a + b*x + c*x^2 + d*x^3 + …$. The purpose of polynomial regression is to capture a wider range of curvature in the data. Unlike linear regression, it’s not limited to linear relationships but can model data with non-linear trends. It’s particularly useful in cases where the relationship between the variables is not straightforward or when you need to model the fluctuations in the data more accurately.
The decision to use Linear Regression or Polynomial Regression depends on the nature of the data and the specific requirements of the analysis. Here are some guidelines to help determine when to use each:
When assessing models trained with Linear and Polynomial Regression, it’s important to choose evaluation metrics wisely, as some are universally applicable while others are better suited to one type of model over the other:
The following are real-world problems examples where linear and polynomial regression may be suitable. In each of these examples, the choice between linear and polynomial regression hinges on the nature of the relationship between the independent and dependent variables. Linear regression excels in scenarios where this relationship is straightforward and linear, while polynomial regression is better suited for more complex, non-linear relationships.
We will illustrate the use of the sklearn module in Python for training linear and polynomial regression models with the California housing dataset.
In the Python code below, sklearn PolynomialFeatures has been used. This class can be understood as a data preprocessing tool that generates polynomial and interaction features from input data. It transforms a dataset with n features into one containing all polynomial combinations up to a specified degree, thereby enhancing the complexity and fit of regression models.
The code PolynomialFeatures(degree=2) creates an instance of the “PolynomialFeatures” class with the degree set to 2. This means it will generate all the polynomial features up to the second degree (squared terms) from the input data. The fit_transform() method first fits the PolynomialFeatures transformer to the training data and then transforms the training data into polynomial features. This includes generating interaction terms (if there are multiple features) and power terms. The transformed training data X_train_poly now contains the original features plus the additional polynomial features. Similar to the training data, X_test is reshaped and then transformed using the already fitted poly_features object. This ensures that the testing data is transformed in the same way as the training data, with the same polynomial features being generated.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
# Load California housing dataset
california = fetch_california_housing()
X = california.data
y = california.target
# For simplicity, let's use the feature "MedInc" which is median income in block group
X_medinc = X[:, california.feature_names.index('MedInc')]
# Splitting the dataset
X_train, X_test, y_train, y_test = train_test_split(X_medinc, y, test_size=0.2, random_state=42)
# Linear Regression
lr = LinearRegression()
lr.fit(X_train.reshape(-1, 1), y_train)
# Polynomial Regression with degree 2
poly_features = PolynomialFeatures(degree=2)
X_train_poly = poly_features.fit_transform(X_train.reshape(-1, 1))
X_test_poly = poly_features.transform(X_test.reshape(-1, 1))
poly_lr = LinearRegression()
poly_lr.fit(X_train_poly, y_train)
# Predictions for plotting
x_range = np.linspace(X_medinc.min(), X_medinc.max(), 100).reshape(-1, 1)
y_lin_pred = lr.predict(x_range)
y_poly_pred = poly_lr.predict(poly_features.transform(x_range))
# Plotting
plt.figure(figsize=(10, 6))
plt.scatter(X_medinc, y, color='gray', alpha=0.5, label='Data points')
plt.plot(x_range, y_lin_pred, color='red', label='Linear Regression')
plt.plot(x_range, y_poly_pred, color='blue', label='Polynomial Regression (Degree 2)')
plt.xlabel('Median Income in Block Group')
plt.ylabel('Median House Value')
plt.title('Linear vs Polynomial Regression on California Housing Dataset')
plt.legend()
plt.show()
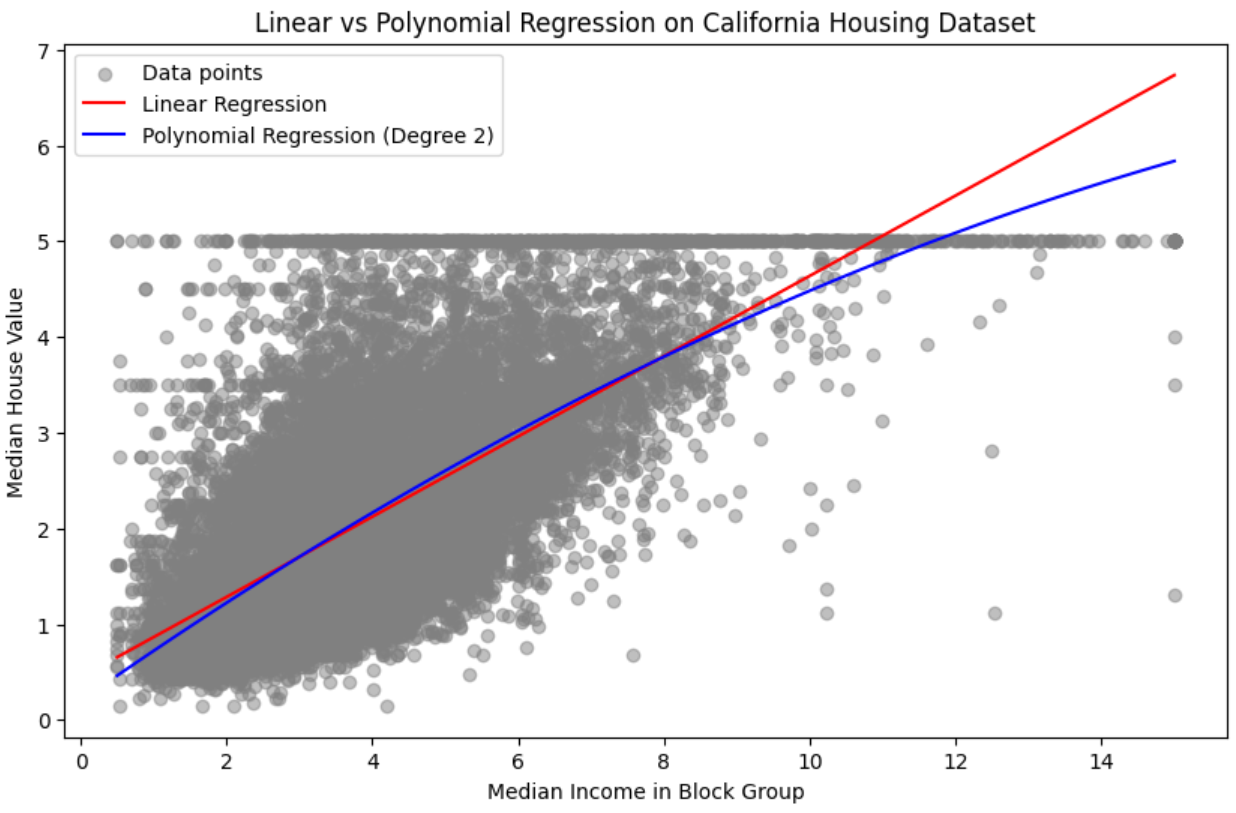
The following plot gets created. The plot displays a comparison between Linear Regression and Polynomial Regression (Degree 2) using the California Housing Dataset. The red line represents the Linear Regression model. It is a straight line that shows the average relationship between the median income and the house value. The blue line represents the Polynomial Regression model with a degree of 2. This line curves to fit the data points better than the straight line of the linear model, indicating the model is capturing some of the non-linear trends in the data.
The Polynomial Regression model appears to fit the lower and higher ends of the income scale more closely than the Linear Regression model, which could suggest a non-linear relationship in the data that the polynomial model is capturing. However, the central part of the plot (around the median income) shows both models giving similar predictions. This visualization is useful for understanding how each model approximates the underlying data distribution and can help in deciding which model might provide better predictions for the dataset at hand.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}