Fig 1. ML Models bias variance vs complexity
In the artificial intelligence (AI) / machine learning (ML) powered world where predictive models have started getting used more often in decision-making areas, the primary concerns of policy makers, auditors and end users have been to make sure that these systems using the models are not making biased/unfair decisions based on model predictions (intentional or unintentional discrimination). Imagine industries such as banking, insurance, and employment where models are used as solutions to decision-making problems such as shortlisting candidates for interviews, approving loans/credits, deciding insurance premiums etc. How harmful it could be to the end users as these decisions may impact their livelihood based on biased predictions made by the model, thereby, resulting in unfair/biased decisions. Thus, it is important for product managers/business analysts and data scientists working on the ML problems to understand different nuances of model prediction bias such as some of the following which is discussed in this post.
Bias in the machine learning model is about the model making predictions which tend to place certain privileged groups at the systematic advantage and certain unprivileged groups at the systematic disadvantage. And, the primary reason for unwanted bias is the presence of biases in the training data, due to either prejudice in labels or under-sampling/over-sampling of data. Given that the features and related data used for training the models are designed and gathered by humans, individual (data scientists or product managers) bias may get into the way of data preparation for training the models. This would mean that one or more features may get left out, or, coverage of datasets used for training is not decent enough. In other words, the model may fail to capture essential regularities present in the dataset. As a result, the resulting machine learning models would end up reflecting the bias (high bias).
Machine learning model bias can be understood in terms of some of the following:
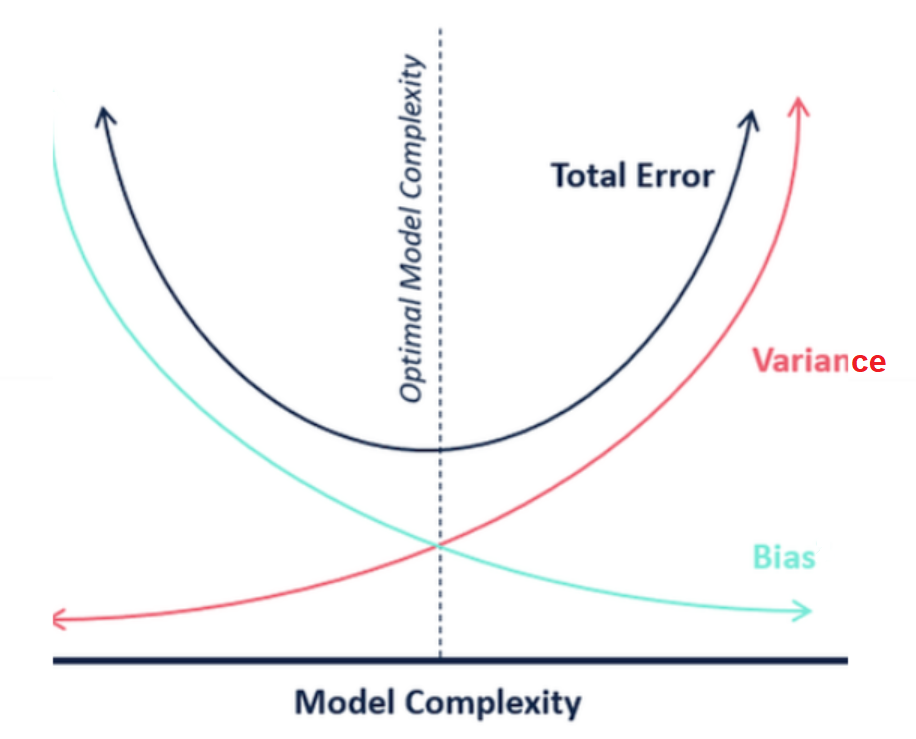
In case the model is found to have a high bias, the model would be called out as unfair and vice-versa. It should be noted that the attempt to decrease the bias results in high complexity models having high variance. The diagram given below represents the model complexity in terms of bias and variance. Note the fact that with a decrease in bias, the model tends to become complex and at the same time, may found to have high variance.
You may note some of the following in the above picture:
It is important to understand how one could go about determining the extent to which the model is biased, and, hence unfair. One of the most common approaches is to determine the relative significance or importance of input values (related to features) on the model’s prediction/output. Determining the relative significance of input values would help ascertain the fact that the models are not overly dependent on the protected attributes (age, gender, color, education etc) which are discussed in one of the later sections. Other techniques include auditing data analysis, ML modeling pipeline etc. Accordingly, one would be able to assess whether the model is fair (unbiased) or not.
In order to determine the model bias and related fairness, some of the following frameworks could be used:
The following are some of the attributes/features which could result in bias:
One would want to adopt appropriate strategies to train and test the model and related performance given the bias introduced due to data related to the above features.
The bias (intentional or unintentional discrimination) could arise in various use cases in industries such as some of the following:
In this post, you learned about the concepts related to machine learning models bias, bias-related attributes/features along with examples from different industries. In addition, you also learned about some of the frameworks which could be used to test the bias. Primarily, the bias in ML models results due to bias present in the minds of product managers/data scientists working on the machine learning problem. They fail to capture important features and cover all kinds of data to train the models which result in model bias. And, a machine learning model with high bias may result in stakeholders take unfair/biased decisions which would, in turn, impact the livelihood & well-being of end customers given the examples discussed in this post. Thus, it is important that the stakeholders pay importance to test the models for the presence of bias.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}