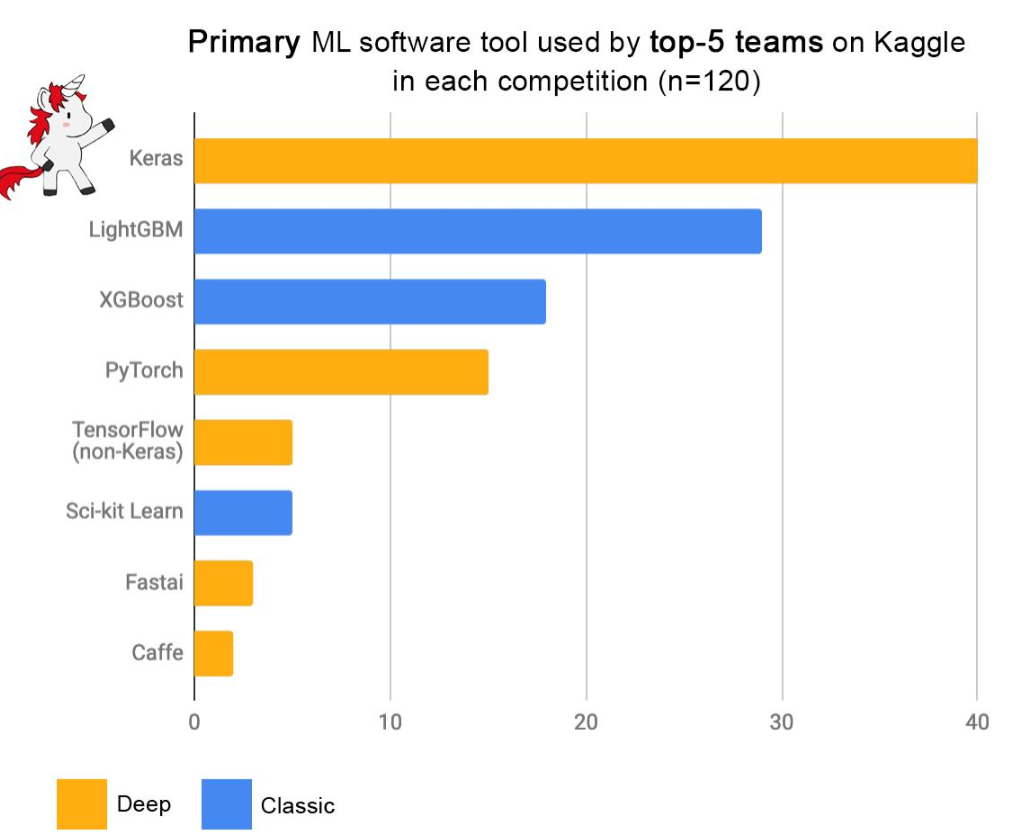
Among the myriad of machine learning algorithms and techniques available with data scientists, one stands out for its exceptional performance in classification problems: XGBoost, short for eXtreme Gradient Boosting. This algorithm has established itself as a force to reckon with in the data science community, as evidenced by its frequent use and high placements in Kaggle competitions, a platform where data scientists and machine learning practitioners worldwide compete to solve complex data problems. The following plot is taken from Francois Chollet tweet.
Above demonstrates the prominence of XGBoost as one of the primary machine learning software tools used by the top-5 teams across 120 Kaggle competitions. The data points in the plot showcase that XGBoost is one of the most preferred choices, surpassing even deep learning giants like TensorFlow and PyTorch in certain contexts.
In this blog, we will delve into the workings of the XGBoost classifier, unpacking its fundamentals and demonstrating its implementation with a Python example using the well-known Iris dataset. Whether you are a beginner looking to understand the basics or an experienced data scientist seeking to refine your toolkit, this walkthrough will provide you with a practical understanding of how XGBoost can be leveraged to solve classification challenges efficiently and with high accuracy.
XGBoost is an advanced implementation of gradient boosting algorithms, widely used for training machine learning models. It’s designed to be highly efficient, flexible, and portable. At its core, XGBoost is a decision-tree-based ensemble machine learning algorithm that uses a gradient boosting framework. Gradient boosting is the backbone of XGBoost. It’s a technique of converting weak learners (simple decision trees) into strong learners in a sequential manner.
The XGBoost classifier operates by sequentially adding predictors (decision trees) to an ensemble, each one correcting its predecessor. Decision trees are the fundamental building blocks of an XGBoost model. Each tree in the ensemble is constructed to predict the residuals (errors) left over by the previous trees. Essentially, every new tree is learning from the mistakes of its predecessors, improving the model’s accuracy with each step. The use of multiple shallow trees, as opposed to a single deep tree, helps in reducing overfitting.
The following is the step-by-step functioning of how XGBoost classifier, or for that matter, XGBoost, works:
XGBoost has become a go-to algorithm for many data scientists for classification tasks, and its popularity is grounded in several compelling reasons. Here are the top three reasons why XGBoost can often be the preferred choice for classification problems:
In this section, we will learn how to train an XGBoost classifier using Python’s XGBoost library in conjunction with the Scikit-learn framework. Sklearn modules are used for data processing, model building, and evaluation. The XGBoost library in Python integrates smoothly with Sklearn, allowing for a familiar and accessible experience for those already comfortable with Sklearn’s workflow.
Before diving into the example, ensure that you have the necessary libraries installed. If not, you can install them using pip:
pip install xgboost pip install scikit-learn
For this example, let’s use the famous Iris dataset, which is a simple yet effective dataset for classification tasks.
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder # Load dataset iris = load_iris() X = iris.data y = iris.target # Split the dataset into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Now, let’s implement the XGBoost classifier. We’ll use the XGBClassifier from the XGBoost package, which is designed to work seamlessly with Sklearn.
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
# Initialize the XGBClassifier
xgb_clf = XGBClassifier()
# Fit the classifier to the training data
xgb_clf.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = xgb_clf.predict(X_test)
# Evaluate the classifier
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
XGBoost offers a variety of parameters that can be tuned to improve performance. Some of the key parameters include:
# Example of a customized XGBoost classifier
custom_xgb_clf = XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=5)
custom_xgb_clf.fit(X_train, y_train)
custom_y_pred = custom_xgb_clf.predict(X_test)
custom_accuracy = accuracy_score(y_test, custom_y_pred)
print(f"Custom Model Accuracy: {custom_accuracy:.2f}")
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}