What is data science? This is a question that many people who are planning to start learning data science are asking, and for good reason. Data science is increasingly being applied to solve real-world issues, encompassing a broad range of areas. In this blog post, we’re going to explore data science: what it is, the methods it employs, and how it’s applied to solve various problems, with relevant examples. Stick with us, and by the end of this post, you’ll gain a comprehensive understanding of data science and its significance!
What is Data Science?
Before understanding what is data science, let’s understand what is science?
Science can be defined as a systematic and logical approach to discovering how things are in the universe. It is a way of acquiring knowledge by using observation and experimentation to describe and explain natural phenomena.
What is data science?
Data science can be defined as an approach to real-world problem solving by establishing and proving newer hypothesis based on acquiring empirical knowledge by leveraging data, algorithms, and technology. Real-world problems can be related to different business domains including healthcare, finance, retail, banking, insurance, etc. These newer hypotheses can also be referred to as insights or actionable insights. Popular scientific methods such as setting hypotheses, experimenting to test the hypothesis, and establishing the hypothesis as true or otherwise also hold good with data science. Data science can be seen as an extension of science but with greater power due to the technology lever related to big data, elastic computing infrastructure to store and process data, programming tools, etc.
How is data science related to machine learning?
Machine learning is an approach to approximating mathematical functions which can be used to make predictions and solve real-world problems. Check out my related post – Machine learning concepts & examples. The approximated mathematical function is termed as machine learning models. It requires data, algorithms and technology to train a machine learning model.
When training models, multiple models can be trained with similar accuracy of predictions. These multiple models can also be understood as the hypotheses. Which model or hypotheses can be most suitable in terms of generalizing to the real-world data can be determined by statistical approaches using statistical tests. The approach of identifying a particular hypothesis as most suitable one falls under the gambit of data science.
Data science framework / methods used
The following represents the framework including some of the key methods which can be used when solving problems using data science:
- Understand problems: Breaking down problems into sub-problems can be helpful. Questioning techniques such as the 5-whys, and the Socratic method can be very helpful. Interacting with end users can also help understand problems better.
- Identify hypotheses to work with: Hypotheses, at times, can be understood as the solution you think can solve the problem. The solution can be hypotheses that can be tested using statistical tests, running simulations based on outcomes of predictive or optimization models, etc. You need to test the solution and find out whether the solution really solves the problem and then establish it for enterprise-wide adoption. For example, running one or marketing campaigns on the customers who are likely to churn out can result in avoiding customer churns. The hypotheses can be around some of the following: A. Deciding one or more particular forms of campaigns that can be most effective B. Identifying the customers who are likely to churn. In one simulation exercise, a set of predictive models can be used to predict and work with the hypothesis that those predictions are correct, e.g, those predicted customers are likely to churn. If the predictions ain’t effective, it will be required to come up with another hypothesis that predicts another set of customers who could churn out. And, in this case, different kinds of predictive models may be required to be built and tested.
- Identify and collect data: Identify key hypotheses/solutions levers and acquire related data (internal or external). Levers are the key attributes that can impact business outcomes when applied. Levers can be represented in form of raw or derived data. Most of these data can be found within the organization. However, one must not be shy of going and getting an external dataset even if it is associated with cost in order to avoid data-related bias.
- Perform data pre-processing including data cleaning, etc: Data in its original form may require some processing in order to prepare data for analysis purposes.
- Perform hypothesis testing (Statistical tests, KPIs, simulations, etc): At times one can test the hypotheses by performing statistical tests. Alternatively, one would need to track KPIs for a certain period of time to accept the hypotheses or solution as a truth. This is where the dashboard could prove to be very helpful. One can also use optimization techniques for prescribing the solution that could be most optimal and run the simulation for a certain period of time to establish the optimization parameters value as truth. One can also use predictive engines or models for estimation purposes and run the simulation exercise (take action) to measure the effectiveness of decisions taken based on the Continuous monitoring holds the key to hypothesis testing.
- Establish new truths to be adopted: As a result of hypothesis testing, or running simulations with optimization or prediction engines, you would be able to establish the truth given the evidence in form of data. This truth can then be established enterprise-wide unless a new truth emerges based on ever-changing data. For example, if a prediction engine is predicting the potential customers who can churn and if a particular kind or form of marketing campaign is run on them, the customer’s churn is found to be reduced. Thus, the predictive engine and the form of marketing can be accepted as truth until the customer’s churn is avoided as desired.
- Continuous monitoring to align solutions/hypotheses: Once the hypotheses have been established as truth, it is of utmost importance to continuously monitor the data and align the solution to ever-changing data. For example, a customer’s behavior might change over time and, in turn, the prediction engine may require re-tuning to predict more accurately. The form of the marketing campaign that was effective earlier for customers who are likely to churn might not be as effective now and would require a different form or mix of campaigns to be run.
Types of Data Science Problems
Data science has the capability to solve an array of complex problems across various domains. The following are different classes of problems which can be solved using data science techniques.
-
Hypothesis Testing to Establish New Truths: Data science plays a crucial role in validating or refuting hypotheses in various fields, from scientific research to market trends. By applying rigorous statistical methods, data scientists can determine the likelihood of a hypothesis being true, thereby paving the way for new discoveries and insights.
-
Statistical Tasks Including Finding Relationships, Regression, etc.: Data science is heavily rooted in statistical analysis, which is used to uncover relationships between variables, predict trends, and understand patterns. Regression analysis, for example, helps in predicting a dependent variable based on one or more independent variables, enabling decision-making in areas like finance, healthcare, and social sciences.
-
Machine Learning Tasks Related to Predictions and Recommendations: One of the most prominent uses of data science is in the field of machine learning, where algorithms are trained to make predictions (regression, classification) or recommendations based on data. This includes everything from predicting customer behavior, stock market trends, to recommending products, movies, or articles based on user preferences.
Examples of Real-world applications of Data Science
Classified into one of the above types, data science has applications related to the following real world problems:
- Risk Assessment: In finance and insurance, machine learning algorithms can assess the risk of investments or insurance policies, making it easier to manage financial risk and make informed decisions.
- Fraud Detection: In banking and e-commerce, data science techniques are employed to detect fraudulent activities by analyzing patterns and anomalies in transaction data.
- Healthcare Diagnostics and Prognostics: In healthcare, data science tools are used for diagnosing diseases from medical imaging, predicting disease outbreaks, and personalizing treatment plans based on patient data.
- Optimizing Supply Chains: In manufacturing and logistics, machine learning is used to optimize supply chains, forecast demand, and improve inventory management, resulting in cost reduction and increased efficiency.
- Energy Consumption Optimization: In the energy sector, data science helps in optimizing power usage, predicting energy demand, and improving renewable energy management.
- Environmental Monitoring and Conservation: Data science aids in analyzing environmental data for monitoring climate change, predicting natural disasters, and aiding in conservation efforts.
What skills you need to become a data scientist?
A data scientist needs to be good with some of the following:
- Good knowledge of business domain; He/she can take help from product managers or business analysts in this area.
- Expert knowledge of statistics: A must-have skill to enable data scientists to design hypotheses, formulate hypotheses in form of the null and alternate hypotheses, and perform hypothesis testing in order to establish the truth to work with.
- Expert knowledge of programming: A must-have skill to enable data scientists to leverage programming knowledge to test the hypothesis, and build predictive models. Programming languages such as Python and R are the most popular ones. Other programming languages include Julia, Scala, and Java.
- Advanced knowledge in data visualization (Desirable): Data scientists should also be adept with at least one of the data visualization tools such as Tableau, Qlikview, and D3.js to communicate the data insights in an effective manner. The tools can help them work with data visualization in a fast manner. They can however do the same thing with Python or R.
- Advanced knowledge of machine learning and optimization algorithms: It would be good to have knowledge of some machine learning algorithms to enable data scientists to find the right pattern in data
- Intermediate knowledge of cloud services: An advanced knowledge of how to operate some of the tools on, at least, one of the clouds such as Amazon, Azure, Google, etc would prove to be very helpful in working with data. The cloud services related to elastic storage and computing infrastructure help working with a vast amount of data and efficient data processing.
- Good knowledge of big data technology: A decent knowledge of some of the big data technology such as Hadoop, Spark, etc may help a great deal.
What are the key outputs of data scientists?
Here are some of the key outputs of projects that data scientists work on:
- Hypotheses formulation and analysis. The hypotheses can be machine learning models or simple statistical tests.
- Establish new truths supported by hypotheses testing; These new truths get adopted and adapted in the organization. The hypotheses can be propositions that can be tracked on the dashboard, and the predictions and optimization output can be tracked as part of the simulation.
- Continuously monitor and re-align the solution to the ever-changing data
Data science is all about understanding problems better, testing hypotheses using data for deriving insights that can help make well-informed decisions thereby improving organizational performance. Thanks for reading! Please feel free to share your thoughts in the comments section below. Do you have any specific examples or case studies in mind? Let us know in the comments below.
Latest posts by Ajitesh Kumar
(see all) 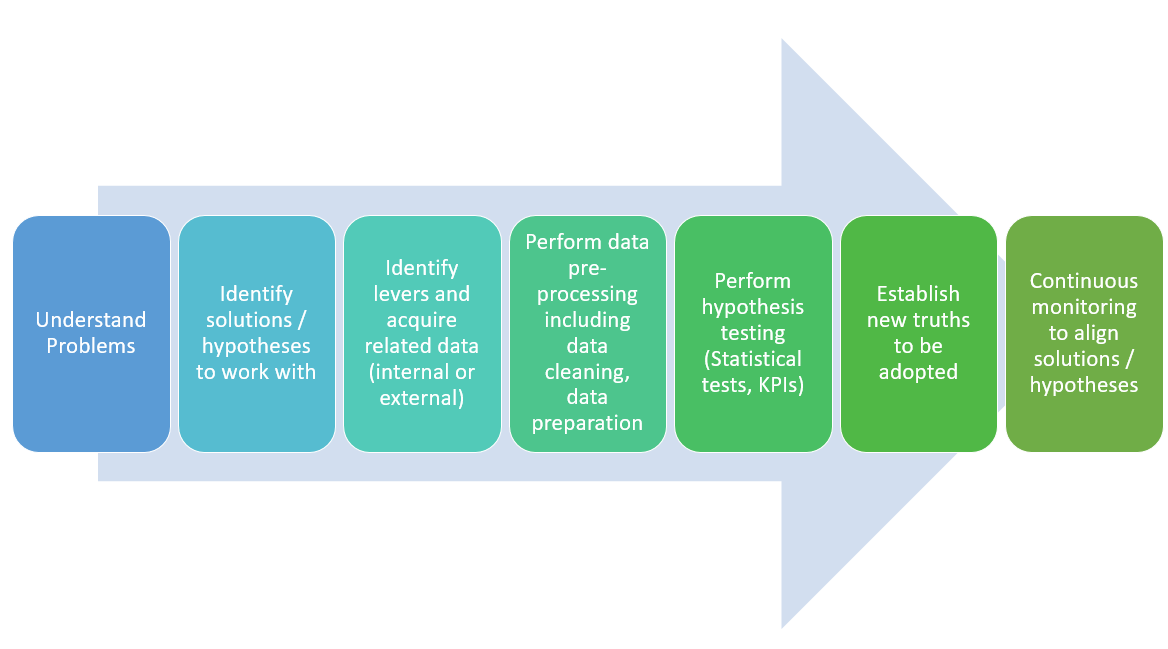{kind=link}