The Transformer model architecture, introduced by Vaswani et al. in 2017, is a deep learning model that has revolutionized the field of natural language processing (NLP) giving rise to large language models (LLMs) such as BERT, GPT, T5, etc. In this blog, we will learn about the details of transformer model architecture with the help of examples and references from the mother paper – Attention is All You Need.
Before getting to understand the details of transformer model architecture, let’s understand the key building block termed transformer block.
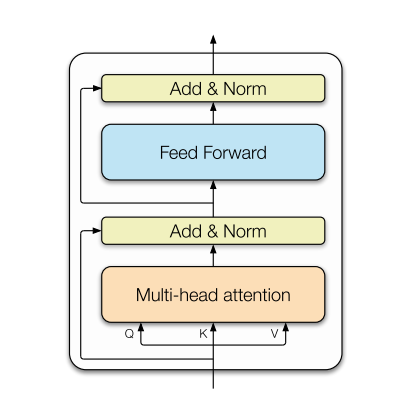
The core building block of the Transformer architecture consists of multi-head attention (MHA)
followed by a fully connected network (FFN) as shown in the following picture (taken from the paper – Scaling down to scaling up: A guide to PEFT). The following transformer block represents a standard component of a transformer model, and multiple such transformer blocks can be stacked to form the full transformer model. At the heart of the transformer model is the attention operation or attention mechanism that allows the modeling of dependencies without regard to their distance in the input or output sequence of text (Attention is all you need). While prior deep learning architectures were based on attention mechanisms in conjunction with recurrent neural networks (RNN), the transformer architecture completely relied on the attention mechanism to draw global dependencies between input and output.
The following are the details of the key building block of the above-shown transformation architecture:
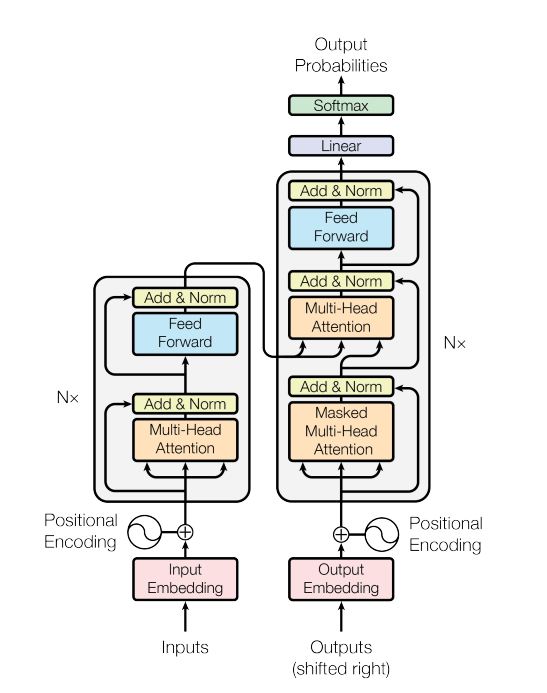
The following is the transformer model architecture (refer Attention is All You Need). The transformer model architecture consists of an encoder (left) and decoder (right) structure. The encoder maps an input sequence of symbol representations (x1, …, xn) to a sequence of continuous representations z = (z1, …, zn). Based on continuous representations, the decoder generates an output sequence (y1, …, ym) of symbols one element at a time.
The following is an explanation of the encoder and decoder blocks of the transformer model architecture shown above:
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}