Overfitting and underfitting represented using Model error vs complexity plot
Last updated: 24th August, 2024
The performance of the machine learning models on unseen datasets depends upon two key concepts called underfitting and overfitting. In this post, you will learn about these concepts and more. In addition, you will also get a chance to test your understanding by attempting the quiz. The quiz will help you prepare well for data scientist interviews.
Assuming an independent and identically distributed (I.I.d) dataset, when the prediction error on both the training and validation dataset is high, and the difference between them is very minimal, the model is said to have underfitted. In this scenario, it becomes cumbersome to reduce the training error. The model is said to be too simple to capture different patterns in the data. This is called underfitting the model or model underfitting.
When the prediction error on the validation dataset is quite high or higher than the training dataset, the model can be said to have overfitted. In other words, when there is a lot of gap between the training and validation error, the model can be said to have been overfitted. This is called model overfitting. Model overfitting is found to happen when model fits the training data too closely, thereby learning noise and outliers present in the data rather than the underlying pattern. As a result, the model performs well on the training data but poorly on unseen or test data.
The picture below represents the case of underfitting and overfitting classification model. Note that in the overfitted model, the separator divides the data most accurately.
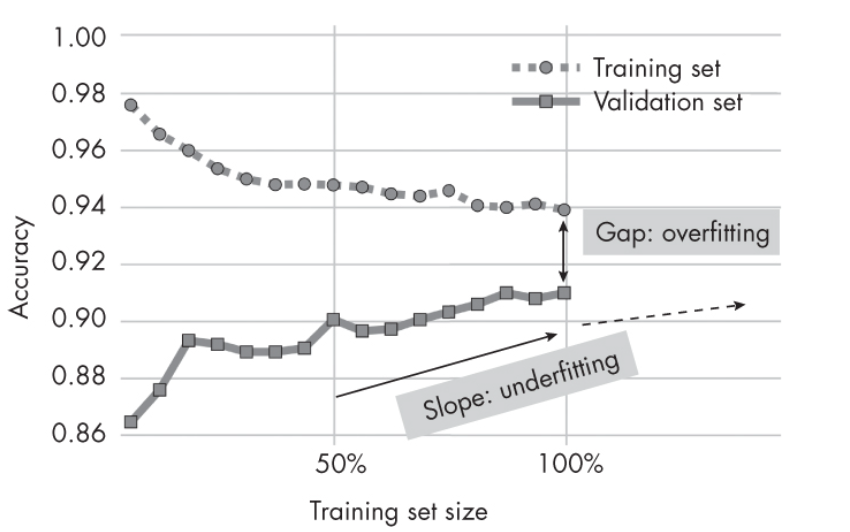
Overfitting of machine learning models happens when the training error is much less than the validation/generalization error. This can happen in some of the following scenarios:
Underfitting of machine learning models happens when you are not able to reduce the training error. This can happen in some of the following scenarios:
Here is a diagram that represents the underfitting vs overfitting in form of model performance error vs model complexity.
In the above diagram, when the model complexity is low, the training and generalization error are both high. This represents the model underfitting. When the model complexity is very high, there is a very large gap between training and generalization error. This represents the case of model overfitting. The sweet spot is in between, represented using a dashed line. At the sweet spot, e.g., the ideal model, there is a smaller gap between training and generalization error.
In order to create a model with decent performance, one should aim to select a decently complex model while avoiding using insufficient training samples.
The way to manage underfitting and overfitting of model in an optimal manner is to manage the model complexity. One of the most important reasons why model overfitting happens is model complexity which happens because of various different reasons such as a large number of model parameters. In such scenarios, the model complexity happening due to a large number of parameters can be resolved using regularization techniques such as L1 or L2 norm. Recall that the regularization technique is used for reducing model overfitting by reducing model complexity. Model complexity is reduced by adding L1 or L2 norm of the weight vector as a penalty term to the problem of minimizing loss. Thus, with one of the L1 or L2 norms, the objective function becomes as minimizing the sum of prediction loss and the penalty term instead of just minimizing the prediction loss to reduce model complexity and hence overfitting. L1 norm is used in what is called LASSO (least absolute shrinkage and selection operator) regression which penalizes several parameters by reducing their value to zero. This technique is popular for feature selection. In the L2 norm which is used in Ridge regression, the model parameters are reduced to very minimal. Various machine learning techniques, including validation curves and cross-fold plots, can be used to spot overfitting.
The ridge regression loss function below represents the L2 penalty term added to loss function of linear regression.
When there are more features than examples, linear models tend to overfit. However, when there are more examples than the features, linear models can be counted upon not to overfit. However, the same is not true for deep neural networks. They tend to overfit even after the fact that there are a lot more examples than the features.
Before getting into the quiz, let’s look at some of the interview questions in relation to overfitting and underfitting concepts:
Here is the quiz which can help you test your understanding of overfitting & underfitting concepts and prepare well for interviews.
That’s all for now on machine learning model overfitting, model underfitting, how they are related to model complexity, and how to reduce model overfitting and underfitting. Remember that a good rule of thumb is to keep your models simple so they are less likely to suffer from overfitting or underfitting problems. You can use the regularization techniques such as L1 norm or L2 norm to reduce model complexity and hence model overfitting. If you have any questions about these concepts or want help implementing them, don’t hesitate to reach out. We would be happy to assist you further!
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
View Comments
noice