Last updated: 1st Feb, 2024
The attention mechanism allows the model to focus on relevant words or phrases when performing NLP tasks such as translating a sentence or answering a question. It is a critical component in transformers, a type of neural network architecture used in NLP tasks such as those related to LLMs. In this blog, we will delve into different aspects of the attention mechanism (also called an attention head), common approaches (such as self-attention, cross attention, etc.) to calculating and implementing attention, and learn the concepts with the help of real-world examples. You can get good details in this book: Generative Deep Learning by David Foster. You might also want to check out this paper from where the Attention concept originated: Attention is all you need.
The attention mechanism or attention head in the transformer is designed in a manner that it can decide where in the input it wants to pull information from, to efficiently extract useful information without being distracted by irrelevant details. This makes it highly adaptable to a range of NLP tasks, as it can decide where it wants to look for information at inference time. This process is similar to how we humans process information by focusing on specific aspects of sentences to infer the next word to be chosen.
Let us understand the concept of attention mechanism with an example. Let’s consider the following sentence:
“The skilled surgeon operated on the patient with a“
In this sentence, the next word after “with a” is influenced by keywords that provide context. Let’s break it down:
In the above example, you might have observed how we are paying attention to certain words in the sentence and largely ignoring others. Wouldn’t it be great if our machine learning model could do the same thing? This is where the attention mechanism or attention head comes into the picture.
The following are some of the most commonly used attention mechanisms:
Self-attention mechanism of the transformer model weighs in the importance of different elements in the input sequence such as the above, and, dynamically adjusting their influence on the output is also called a self-attention mechanism. As per the paper, Attention is all you need, self-attention, sometimes called intra-attention is an attention mechanism that relates different positions of the input sequence to compute a representation of the sequence. It is called as intra-attention as all the queries, keys, and values come from the same block (encoder or decoder).
The transformer model relies on the self-attention mechanism to compute representations of its input and output. Self-attention mechanism is referred to as the scaled dot-product attention mechanism in the original paper. You would want to check out the following post to get a further understanding of self-attention – Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs.
Another type of attention mechanism is called the cross-attention mechanism in which the encoder processes the input data and generates a set of representations. These representations then serve as the “memory” that the decoder accesses to generate the output. Specifically, in cross-attention, the decoder’s intermediate representations are used as queries, while the encoder’s outputs provide the keys and values. This mechanism allows each position in the decoder to attend overall positions in the encoder’s output, thus enabling the decoder to focus on relevant parts of the input sequence when generating each token in the output sequence. This is crucial for tasks like machine translation, where the output sequence needs to be conditioned on the entire input sequence.
Full attention is the original self-attention mechanism as introduced in the Transformer architecture. It computes the attention scores between all pairs of positions in the input sequence, resulting in a quadratic complexity.
The self-attention has a quadratic time complexity of O(n2), which becomes prohibitive when scaling the LLMs to large context windows. This is where sparse attention comes into the picture.
Flash attention addresses the bottleneck of memory access in the calculation of attention mechanisms, particularly when using GPUs. Traditional attention mechanisms, including sparse attention, often require frequent data transfers between the GPU’s high-bandwidth memory (HBM) and its processing units, which can be a significant bottleneck. Flash attention optimizes this by using an input tiling approach, where blocks of the input are processed in the GPU’s on-chip SRAM (Static Random-Access Memory), thus reducing the need for constant I/O operations.
Attention mechanisms in transformer models rely on a concept called Query, Keys, and Values to decide where to look for the key information or where to pay attention. The attention head can be thought of as a kind of information retrieval system as a function of (Q, K, V), where a query (“What word follows with a?”) is made into a key/value store (other words in the sentence) and the resulting output is a sum of the values, weighted by the relationship between the query and each key.
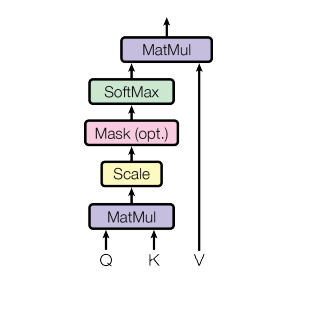
In transformer models, each attention head (self-attention) has its own associated set of Query (Q), Key (K), and Value (V) vectors. This design is part of what makes the multi-head attention mechanism in Transformers particularly powerful. The following is a diagrammatic representation of self-attention. It is also called scaled dot-product attention. As shown below, the input consists of queries and keys of dimension Dk and values of dimension Dv. We compute the dot products of the query with all keys, divide each by √Dk, and apply a softmax function to obtain the weights on the values. Check out this paper for greater details – Attention is all you need.
The following represents the formula of the attention mechanism as a function of Q, K, and V. The input is a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V.
$\Large \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{D_k}}\right)V$
Let’s break down the concepts of Queries, Keys, and Values in the attention mechanism step-by-step, using the example sentence “The skilled surgeon operated on the patient with a”:
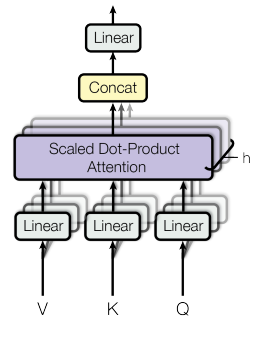
Multihead attention or Multihead self-attention in a transformer represents multiple attention heads where each attention head learns a distinct attention mechanism so that the layer as a whole can learn more complex relationships. The following represents the multi-head attention or multihead self-attention mechanism working in parallel.
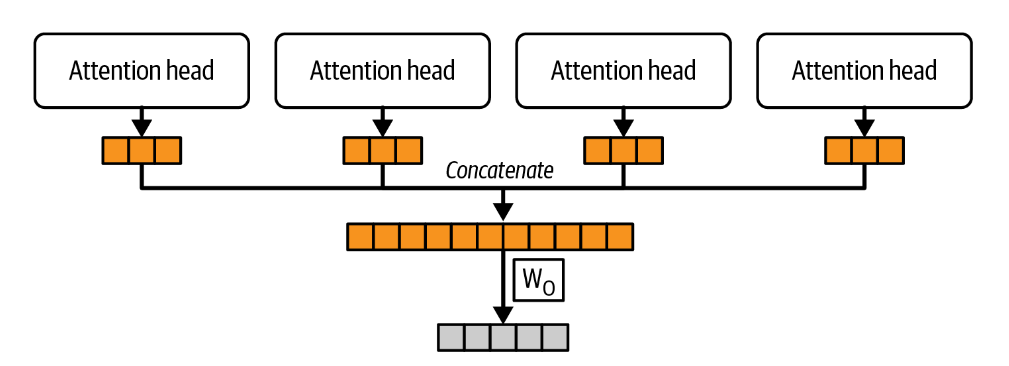
As shown above, the multiple attention heads operate in parallel while each attention head focuses on different aspects or parts of the input sequence. For example, one head might focus on syntactic features while another might capture semantic relationships. Each attention head computes its own set of Q, K, and V vectors. Once each head has its Q, K, and V vectors, it performs the attention computation independently. This involves calculating attention scores, which determine how much focus each element of the input sequence (represented by the Key vectors) should receive when producing each part of the output sequence (represented by the Query vectors). After each head computes its attention output, the concatenated outputs are passed through one final weights matrix to produce the final output of the multi-head attention layer. The final output is projected in the form of a vector into the desired output dimension.
The following picture depicts the working of multi-head attention:
In the above picture, note how the outputs from multiple attention heads are concatenated and passed through weight matrix W0 to produce the final output.
The following represents the usage of a multihead attention mechanism in the transformer. Read the details in Attention is all you need.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
{kind=link}