Have you ever wondered how to build a scalable Generative AI platform based on OpenAI GPT models that can serve different applications? Are you a data scientist, product manager, or software engineer looking to understand the intricacies of the architecture of such a scalable generative AI platform? This blog aims to demystify the architectural building blocks needed to create a robust GPT-based platform. By the end, you will have a clear roadmap for architecting, designing, and implementing your own GPT-based large language models (LLMs) applications platform.
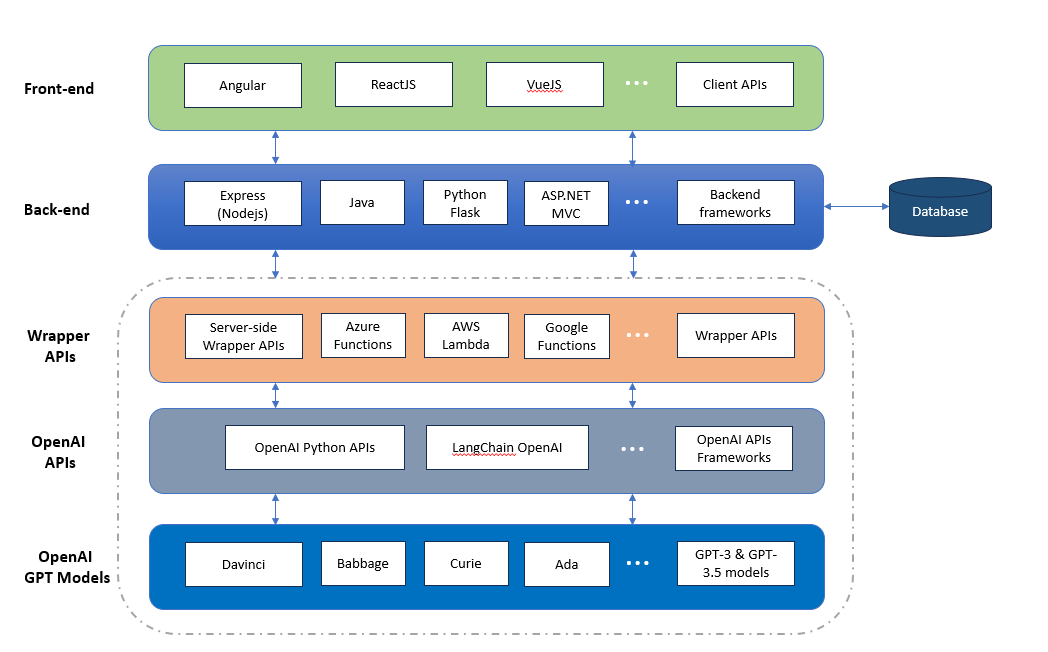
The following is the technology architecture of generative AI platform which can leverage OpenAI GPT based models for LLM use cases related to text generation, text completion, text summarization, conversation, etc.
The following are key building blocks of the generative AI platform represented in the above diagram. Note that the wrapper APIs, OpenAI APIs and GPT models shown in the above picture (within dashed line) form the part of the platform. They would be mostly same and enhanced from time-to-time. There can be different client / frontend and server / backend apps. For smaller organizations, one can also form the server side application as part of the platform. What will vary will be mostly client side or front end apps.
Navigating the complex landscape of generative AI platforms can be a daunting task, especially for smaller organizations with limited resources. However, as we’ve explored in this comprehensive guide, a well-thought-out architecture can alleviate many of these challenges. By understanding the pivotal roles of different components—from the front-end app that interfaces with users to the server-side app that acts as the workhorse—we can design a scalable, efficient, and cost-effective platform. For smaller organizations, the idea of leveraging a single server-side app to serve multiple client-side applications is particularly compelling. It allows for streamlined operations, reduced costs, and quicker deployment of new features or applications. With the help of serverless technologies, even the Wrapper API layer can be efficiently managed, freeing up developers to focus on what truly matters: building powerful, AI-driven applications that solve real-world problems.
Whether you’re a data scientist seeking to deploy machine learning models, a product manager aiming to bring an AI-driven service to market, or a software engineer tasked with building a robust application, understanding these architectural principles is crucial. It provides you not just with a blueprint for current projects, but also equips you with the knowledge to adapt and evolve in the ever-changing world of generative AI.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}