NLP has been around for decades, but it has recently seen an explosion in popularity due to pre-trained models (PTMs), also termed foundation models. This blog post will introduce you to different types of pre-trained (a.k.a. foundation) machine learning models and discuss their usage in real-world examples.
Before we get into looking at different types of pre-trained models in NLP, let’s understand the concepts related to pre-trained models.
What are Pre-trained Models?
Pre-trained models (PTMs) are very large and complex neural network-based deep learning models, such as transformers, that consist of billions of parameters (a.k.a. weights) and have been trained on very large datasets to perform specific NLP tasks. The parameters or weights are learned during the training phase, often called pre-training. The training spans weeks or months on a large number of GPUs. By training on extensive corpora, PTMs can learn universal language representations based on encoder-only (such as BERT) or decoder-only transformer (such as GPT) architecture (or both encode-decoder such as T5), which are useful for various downstream NLP tasks such as text summarization, named entity recognition, sentiment analysis, part-of-speech tagging, language translation, sentiment analysis, text generation, information retrieval, text clustering, and many more. This eliminates the need to train a new model from scratch each time. In other words, pre-trained models can be understood as reusable NLP models that developers can use to quickly build NLP applications.
For example, with pre-trained models, we can summarize lengthy articles into concise paragraphs, extract important entities such as names, organizations, and locations from text, classify sentiment in customer reviews, determine the grammatical category of each word in a sentence, translate text from one language to another, generate human-like responses in chatbots, retrieve relevant information from a large corpus, group similar documents together based on their content, and so on.
Transformers offer a range of pre-trained deep learning NLP models that cater to different tasks like text classification, question answering, and machine translation. These pre-trained models can be found on websites such as Hugging Face Model Hub, and PyTorch Hub. While the first generation of PTMs focused on learning good word embeddings, the latest or second generation is designed to learn contextual word embeddings. I’ll delve into the details of different types of pre-trained models in my upcoming blogs.
When starting with pre-trained models, you can choose to start with smaller foundation models (for example, one trained with 7 billion parameters) that can be executed on relatively smaller sizes of hardware. If working on the cloud, you can get started with Amazon SageMaker JumpStart or Amazon Bedrock.
Examples of pre-trained / foundation models publicly available are Llama2, Falcon, Stable Diffusion, etc. Some of the proprietary models include AI21, Cohere, LightOn, etc.
Pre-trained models can be easily loaded into NLP libraries such as PyTorch, Tensorflow, etc, and used for performing NLP tasks with almost no extra effort required from NLP developers. Pre-trained models are getting used more and more often on NLP tasks because they are easier to implement, have high accuracy, and require less training time compared to custom-built models.
How are pre-trained or foundation models and transfer learning related?
Generally speaking, pre-trained models and transfer learning are closely related concepts in machine learning.
As explained earlier, pre-trained / foundation models are trained on a large dataset for a specific task, such as image recognition or natural language processing. These models are trained to learn general patterns and features that can be applied to other specific tasks.
Transfer learning is a machine learning technique where a pre-trained model is used as a starting point for a new task. The idea is to use the knowledge learned from the pre-trained model on a new dataset that may be different from the one used for training the pre-trained model. This approach can save significant time and resources compared to training a new model from scratch.
The relationship between pre-trained models and transfer learning is that pre-trained models are often used as a starting point for transfer learning. By leveraging the knowledge learned from a pre-trained model on a new task, transfer learning can often achieve higher accuracy with less data and computation. The picture below represents how a common pre-trained model can be reused (based on transfer learning) for different tasks resulting in task specific network.
One real-world example of how NLP pre-trained models and transfer learning are used is in the development of chatbots for customer service. NLP pre-trained models and transfer learning can be used to simplify the development of chatbots. Pre-trained models such as BERT (Bidirectional Encoder Representations from Transformers) or GPT-3 (Generative Pre-trained Transformer 3) can be fine-tuned on a specific domain, such as customer service inquiries, to provide accurate responses. The pre-trained model is initially trained on a large corpus of text data, such as Wikipedia, to learn general language patterns and features. Then, the model is fine-tuned on a smaller dataset of customer service inquiries to learn specific features and patterns that are relevant to the task at hand. For example, a financial services company may use pre-trained NLP models to build a chatbot that can understand customer inquiries related to account balances, transaction history, or investment options. By fine-tuning the pre-trained models on a dataset of financial service inquiries, the chatbot can provide accurate responses and improve customer satisfaction.
Pre-trained model when combined with a transfer learning method can save significant time and resources compared to training a new NLP model from scratch.
What are some real-world NLP examples where pre-trained models are used?
Some real-world and most popular examples where pre-trained NLP models are getting used are the following:
- Named Entity Recognition (NER) is an NLP task where the model tries to identify the type of every word/phrase that appears in the input text. For example, given a sentence like “Chris Cairns was born on August 14th, 1980”, NER should recognize “Chris Cairns” as a person’s name, “August 14th” as the date, and “1980” as the year. NER models are getting used in many scenarios like spam detection, customer support & chatbots, etc. There are several examples of pre-trained NER models provided by popular open-source NLP libraries such as NLTK, Spacy, Stanford CoreNLP , BERT, etc. These models can be loaded with Tensorflow or PyTorch and executed for NER tasks.
- Sentiment Analysis is an NLP task where a model tries to identify if the given text has positive, negative, or neutral sentiment. Sentiment analysis can be used in many real-world scenarios like customer support chatbots and spam detection. Pre-trained NLP models for sentiment analysis are provided by open-source NLP libraries such as BERT, NTLK, Spacy, and Stanford NLP.
- Machine Translation is an NLP task where a model tries to translate sentences from one language into another. NER models are often used as part of the machine translation pipeline for pre-processing input text before sending it over to the Translate Model which performs actual sentence translations using Neural Machine Translation (NMT) models. NER and NMT are often combined to achieve better results than NER or NMT alone, as NER pre-processes the input text by removing stopwords and other unimportant words that do not contribute much towards an understanding of the sentence. Then NMT receives a clean version of each sentence in both source and target languages. NER and NMT models are pre-trained by popular open-source NLP libraries such as OpenNMT, BERT-NMT, etc.
- Text Summarization is an NLP task where a model tries to summarize the input text into a shorter version in an efficient way that preserves all important information from the input text. NER, NMT, and Sentiment Analysis models are often used as part of the pipeline for pre-processing input text before sending it over to a summarization model. Some popular open-source NLP libraries like Stanford CoreNLP offer these NLP pipelines consisting of NER, NMT or sentiment analysis, and summarization NLP models. Transformers and NLP libraries such as BERT, GPT, etc could be used for text summarization.
- Natural Language Generation is an NLP task where the model tries to generate natural language sentences from input data or information given by NLP developers. Pre-trained NLP models for NLG are getting used to generate personalized content like emails, social media posts, etc. One does not need to write the entire code of generating sentences from data/information because pre-trained NLP models can be easily implemented with less effort and time compared to custom-built NLP models.
- Speech Recognition is an NLP task where a model tries to identify what the user is saying. NLP pre-trained models for speech recognition are getting used in many NLP libraries/APIs that are available online like Amazon Alexa, Google API, etc. Speech recognition can be implemented with high accuracy on NLP tasks by using NLP pre-trained models on NLP APIs from different companies/developers.
- Content Moderation is an NLP task where a model tries to identify the content that might be inappropriate (offensive/explicit), or should not be shown on public channels like social media posts, comments, etc. NLP pre-trained models for content moderation are getting used in NLP APIs like Clarifai API, Google Cloud NLP API, Microsoft Azure Cognitive Services Text Analytics API, etc.
- Automated Question Answering Systems (QA): Automated QA systems try to answer user-defined questions automatically by looking at the input text. NER is one of the key components in such systems because it allows QA systems to identify what type of question they need to answer and extract the relevant information from the input text for answering that specific question.
What are the different services/libraries that provide NLP pre-trained models?
There are several open-source libraries/cloud services that provide pre-trained models accessible for NLP, each tailored to a certain type of NLP task. Some of the most popular ones are listed below:
- Google BERT: BERT stands for Bidirectional Encoder Representations from Transformers and it is a state-of-the-art machine learning model used for NLP tasks. Jacob Devlin and his colleagues developed BERT at Google in 2018. It was made open source in March 2019, as part of the TensorFlow project to make it easier for developers and data scientists to build AI models using existing state-of-the-art algorithms like BERT. BERT has been trained on NLP tasks like NER, sentence segmentation, part-of-speech tagging, etc.
- CodeBERT: NLP engineers at Microsoft have published their NLP pre-trained model, CodeBERT, on GitHub. CodeBERT is a bimodal pre-trained model for programming languages (PL) and natural language (NL). CodeBERT learns general-purpose representations that support downstream NL-PL applications such as natural language code search, code documentation generation, etc. CodeBERT is developed with transformer-based neural architecture, and trained with a hybrid objective function that incorporates the pre-training task of replaced token detection, which is to detect plausible alternatives sampled from generators. Here is the page for a detailed read
- Huggingface transformers: Huggingface provides pipeline APIs for grouping different pre-trained models for different NLP tasks. Check out supported transformers on the GitHub page including BERT, Roberta, GPT-2, XLNet, BlenderBot, etc.
- OpenNMT: OpenNMT is an open-source ecosystem for neural machine translation and neural sequence learning. Started in December 2016 by the Harvard NLP group and SYSTRAN, the project has since been used in several research projects and industrial applications. It is currently maintained by SYSTRAN and Ubiqus. NER models are often used as part of the machine translation pipeline for pre-processing input text before sending it over to the Translate Model which performs actual sentence translations using Neural Machine Translation (NMT) models.
- Facebook RoBERTa: NLP engineers at Facebook have published their NLP pre-trained model, RoBERTa, on GitHub. Roberta has been used in NLP applications like Facebook Messenger, NLP API, etc. Roberta improves upon Bidirectional Encoder Representations from Transformers, or BERT, the self-supervised method released by Google in 2018. RoBERTa builds on BERT’s language masking strategy, wherein the system learns to predict intentionally hidden sections of text within otherwise unannotated language examples.
- ELMo: ELMo stands for “Embeddings from Language Models”. The pre-trained model is developed at Allen AI Research Center by NLP scientists. It was made open source in March 2019, as part of the TensorFlow project to make it easier for developers and data scientists to build AI models using existing state-of-the-art algorithms like ELMo. ELMo is a deeply contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). These word vectors are learned functions of the internal states of a deep bidirectional language model (BLM), which is pre-trained on a large text corpus. They can be easily added to existing models
- GPT-3: GPT-3 is an autoregressive language model that uses deep learning to produce human-like text. It is the third-generation language prediction model in the GPT-n series (and the successor to GPT-2) created by OpenAI, a San Francisco-based artificial intelligence research laboratory.
- XLNet: XLNet is a new unsupervised language representation learning method based on a novel generalized permutation language modeling objective. Additionally, XLNet employs Transformer-XL as the backbone model, exhibiting excellent performance for language tasks involving long context.
- ULMFit: ULMFit enables robust inductive transfer learning for any NLP tasks, akin to fine-tuning ImageNet models: The same 3-layer LSTM architecture— with the same hyperparameters and no additions other than tuned dropout hyperparameters.
NLP pre-trained models are useful for NLP tasks like translating text, predicting missing parts of a sentence or even generating new sentences. NLP pre-trained models can be used in many NLP applications such as chatbots and NLP API etc. There are many types of pre-trained models that you could use to get started with NER, text summarization, NMT (Neural Machine Translation), or NLG (Natural Language Generation), depending on your project needs. These include CodeBERT, OpenNMT, RoBERTa, GPT-3, etc. Greater details regarding each type of pre-trained model and libraries will be posted soon.
Latest posts by Ajitesh Kumar
(see all) 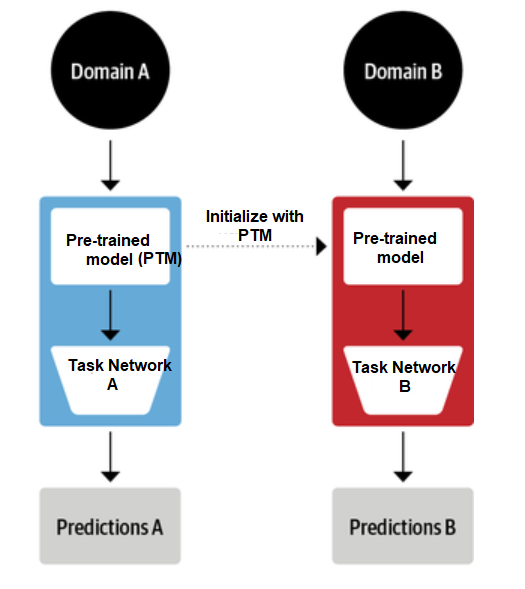{kind=link}