Last updated: 25th August, 2024
In machine learning, model complexity and overfitting are related in that the model overfitting is a problem that can occur when a model is too complex for different reasons. This can cause the model to fit the noise & outliers in the data rather than the underlying pattern. As a result, the model will perform poorly when applied to new and unseen data. In this blog post, we will discuss model complexity and how you can avoid overfitting in your models by handling the complexity. As data scientists, it is of utmost importance to understand the concepts related to model complexity and how it impacts the model overfitting.
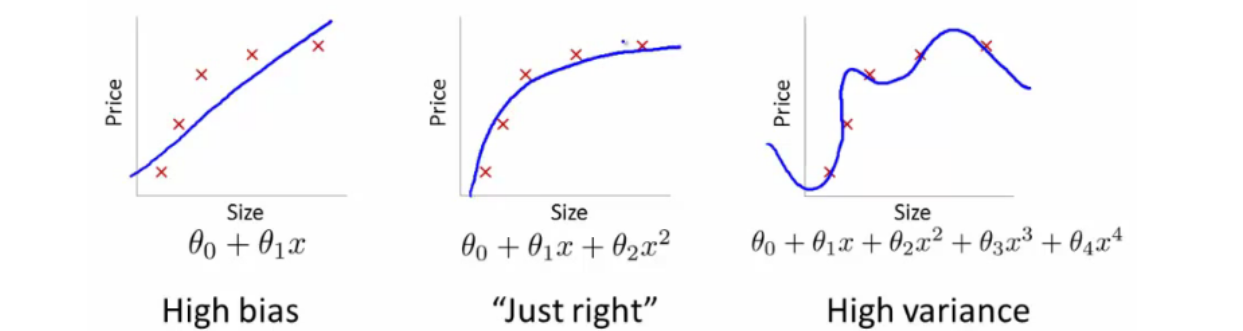
Model complexity is a key consideration in machine learning. Simply put, it refers to the number of predictor or independent variables or features that a model needs to take into account to make accurate predictions. For example, a linear regression model with just one independent variable is relatively simple, while a model with multiple variables or non-linear relationships is more complex. A model with a high degree of complexity may be able to capture more variations in the data, but it will also be more difficult to train and may be more prone to overfitting. On the other hand, a model with a low degree of complexity may be easier to train but may not be able to capture all the relevant information in the data. Finding the right balance between model complexity and predictive power is crucial for successful machine learning. The picture below represents a complex model (extreme right) vis-a-vis a simple model (extreme left). Note the aspect of some parameters vis-a-vis model complexity.
Model complexity is a measure of how accurately a machine learning model can predict unseen data, as well as how much data the model needs to see to make good predictions. Model complexity is an important consideration because it determines how generalizable a model is – that is, how well the model can be used to make predictions on new, unseen data. With simple models and abundant data, the generalization error is expected to be similar to the training error. With more complex models and fewer examples, the training error is expected to go down but the generalization gap grows which can also be termed model overfitting.
The following are key factors that govern the model complexity and impact the model accuracy with unseen data:
Why is model complexity important? Because as models become more complex, they are more likely to overfit the training data. This means that they may perform well on the training set but fail to generalize to new data. In other words, the model has learned too much about the specific training set and has not been able to learn the underlying patterns. As a result, it is essential to strike the right balance between model complexity and overfitting when developing machine learning models.
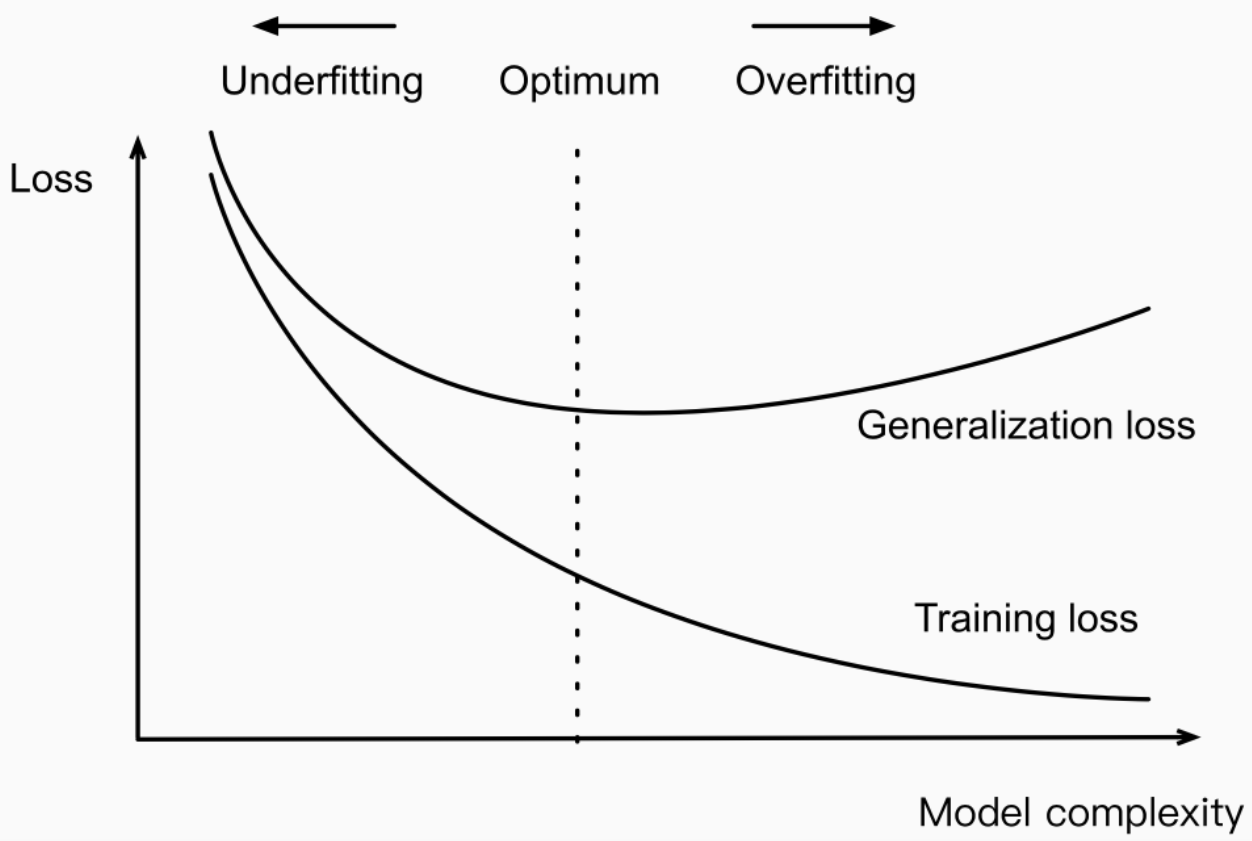
Model overfitting occurs when a machine learning model is too complex, captures noise in the training data instead of the underlying signal, and therefore does not generalize well to new data. This is usually due to the model having been trained on too small of a dataset, or on a dataset that is too similar to the test dataset. The picture below represents the relationship between model complexity and training/test (generalization) prediction error.
Note some of the following in the above picture:
In the case of neural networks, model complexity can be increased by adding more hidden layers to the model, or by increasing the number of neurons in each layer. Model overfitting can be prevented by using regularization techniques such as dropout or weight decay. When using these techniques, it is important to carefully choose the appropriate level of regularization, as too much regularization can lead to underfitting.
In machine learning, one of the main goals is to find a model that accurately predicts the output for new input data. However, it is also important to avoid both model complexity and overfitting. When models are too complex, they tend to overfit the training data and perform poorly on new, unseen data. This is because they have learned the noise in the training data rather than the underlying signal. Model complexity can also lead to longer training times and decreased accuracy while overfitting can cause the model to perform well on the training data but poorly on new data. There are a few ways to prevent these problems.
Model complexity and overfitting are two of the main problems that can occur in machine learning. Model complexity can lead to a model that is too complex and does not generalize well to new data, while overfitting can cause the model to perform well on the training data but poorly on new data. There are several ways to prevent these problems, including using simpler models, using regularization techniques, splitting the data into a training set and a test set, early stopping, and cross-validation. It is important to monitor the performance of the model as it is being trained and adjust the parameters accordingly.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}