MinMaxScaler vs StandardScaler
Last updated: 7th Dec, 2023
Feature scaling is an essential part of exploratory data analysis (EDA), when working with machine learning models. Feature scaling helps to standardize the range of features and ensure that each feature (continuous variable) contributes equally to the analysis. Two popular feature scaling techniques used in Python are MinMaxScaler and StandardScaler.
In this blog, we will learn about the concepts and differences between these feature scaling techniques with the help of Python code examples, highlight their advantages and disadvantages, and provide guidance on when to use MinMaxScaler vs StandardScaler. Note that these are classes provided by sklearn.preprocessing module. As a data scientist, you will need to learn these concepts in order to train machine learning models using algorithms that require features to be on the same scale.
Both MinMaxScaler and StandardScaler scale the data (features), but they use different methods to achieve this. MinMaxScaler scales the data to a fixed range, typically between 0 and 1. On the other hand, StandardScaler rescales the data to have a mean of 0 and a standard deviation of 1. The following is the list of some of the key differences between StandardScaler and MinMaxScaler:
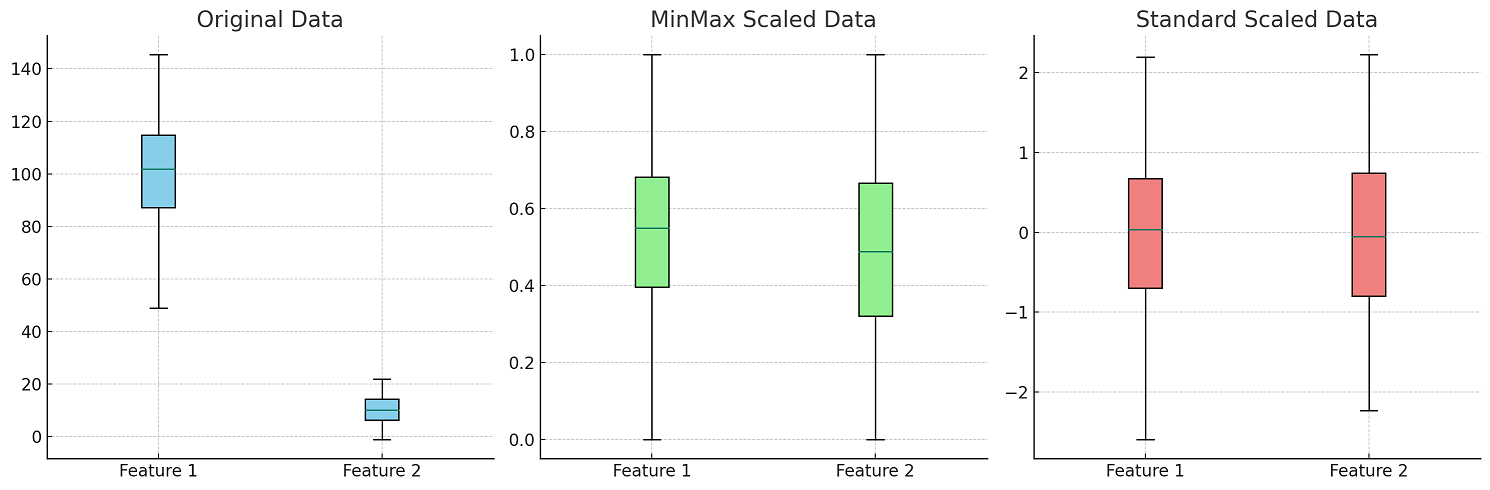
The following is a visual representation of application of Min Max Scaler and Standard Scaler.
Note some of the following in the above plot:
Here is the sample Pandas data frame which will be used later in this post for illustration of StandardScaler and MinMaxScaler:
import pandas as pd
import numpy as np
arr = np.array([['M', 81.4, 82.2, 44, 6.1, 120000, 'no'],
['M', 75.2, 86.2, 40, 5.9, 80000, 'no'],
['F', 80.0, 83.2, 34, 5.4, 210000, 'yes'],
['F', 85.4, 72.2, 46, 5.6, 50000, 'yes'],
['M', 68.4, 87.2, 28, 5.11, 70000, 'no']])
#
# Create Pandas DataFrame
#
df = pd.DataFrame(arr)
df.columns = ['gender', 'hsc_p', 'ssc_p', 'age', 'height', 'salary', 'suffer_from_disease']
#
# Convert the string data type to int and float appropriately
#
df[['age', 'salary']] = df[['age', 'salary']].astype(int)
df[['ssc_p', 'hsc_p', 'height']] = df[['ssc_p', 'hsc_p', 'height']].astype(float)
Here is how the data frame looks like:
Feature scaling is about transforming the values of different numerical features to fall within a similar range like each other. The feature scaling is used to prevent the supervised learning models from getting biased toward a specific range of values. For example, if your model is based on linear regression and you do not scale features, then some features may have a higher impact than others which will affect the performance of predictions by giving undue advantage for some variables over others. This puts certain classes at disadvantage while training model. This is why it becomes important to use scaling algorithms such as standard scaling or min max scaling.
This process of feature scaling is done so that all features can share the same scale and hence avoid problems such as some of the following:
Scaling the data to a common range can help to alleviate this problem. In this case, we can use the MinMaxScaler or StandardScaler to scale the data so that the features such as the salary, age and income contribute equally to the analysis. By scaling the data, we can ensure that each feature has an equal impact on the model’s performance, and the model can make more accurate predictions.
Feature scaling is not important for algorithms such as random forest or decision trees which are scaling invariant. The scale of the value of the feature does not impact the model performance of models trained using these algorithms (random forest/decision tree).
The two common approaches to bringing different features onto the same scale are normalization and standardization. Normalization (also called Min max Scaling) is implemented in Python using MinMaxScaler and the standardization (also known as Standard Scaling) is implemented using StandardScaler.
Normalization refers to the rescaling of the features to a range of [0, 1], which is a special case of min-max scaling. To normalize the data, the min-max scaling can be applied to one or more feature columns. Here is the formula for normalizing data based on min-max scaling. Normalization is useful when the data is needed in the bounded intervals.
This is how the Python method would look like for normalizing one or more columns:
def normalize(values):
return (values - values.min())/(values.max() - values.min())
In order to apply the normalization technique to one or more feature columns, one could use the following Python code (with reference to the dataset used in this post). Note the usage of apply method which applies the normalize method shown above on multiple feature columns all at once.
cols = ['hsc_p', 'ssc_p', 'age', 'height', 'salary']
#
# Normalize the feature columns
#
df[cols] = df[cols].apply(normalize)
The standardization technique is used to center the feature columns at mean 0 with a standard deviation of 1 so that the feature columns have the same parameters as a standard normal distribution. Unlike Normalization, standardization maintains useful information about outliers and makes the algorithm less sensitive to them in contrast to min-max scaling, which scales the data to a limited range of values. Here is the formula for standardization.
This is how the Python method would look like for standardizing one or more columns:
def standardize(values):
return (values - values.mean())/values.std()
In order to apply the standardization techniques to one or more feature columns, one could use the following Python code (with reference to the dataset used in this post). Note the usage of apply method which applies the standardize method on multiple feature columns all at once.
cols = ['hsc_p', 'ssc_p', 'age', 'height', 'salary']
#
# Standardize the feature columns; Dataframe needs to be recreated for the following command to work properly.
#
df[cols] = df[cols].apply(standardize)
MinMaxScaler is a class from sklearn.preprocessing which is used for normalization. Here is the sample code:
from sklearn.preprocessing import MinMaxScaler
mmscaler = MinMaxScaler()
cols = ['hsc_p', 'ssc_p', 'age', 'height', 'salary']
df[cols] = mmscaler.fit_transform(df[cols])
In case of normalizing the training and test data set, the MinMaxScaler estimator will fit on the training data set and the same estimator will be used to transform both training and the test data set. The following code demonstrates the same assuming X consists of the training data set and y consists of corresponding labels. IRIS data set is used for illustration purposes.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
mmscaler = MinMaxScaler()
X_train_norm = mms.fit_transform(X_train)
X_test_norm = mms.transform(X_test)
StandardScaler is a class from sklearn.preprocessing which is used for standardization. Here is the sample code:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
cols = ['hsc_p', 'ssc_p', 'age', 'height', 'salary']
df[cols] = sc.fit_transform(df[cols])
In case of standardizing the training and test data set, the StandardScaler estimator will fit on the training data set and the same estimator will be used to transform both training and the test data set. The following code demonstrates the same. IRIS data set is used for illustration purposes.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
sc = StandardScaler()
X_train_norm = sc.fit_transform(X_train)
X_test_norm = sc.transform(X_test)
MinMaxScaler is useful when the data has a bounded range or when the distribution is not Gaussian. For example, in image processing, pixel values are typically in the range of 0-255. Scaling these values using MinMaxScaler ensures that the values are within a fixed range and contributes equally to the analysis. Similarly, when dealing with non-Gaussian distributions such as a power-law distribution, MinMaxScaler can be used to ensure that the range of values is scaled between 0 and 1.
StandardScaler is useful when the data has a Gaussian distribution or when the algorithm requires standardized features. For example, in linear regression, the features need to be standardized to ensure that they contribute equally to the analysis. Similarly, when working with clustering algorithms such as KMeans, StandardScaler can be used to ensure that the features are standardized and contribute equally to the analysis.
Here are some conclusions you can take away as the learning:
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}