Maximum Likelihood Estimation (MLE) is a fundamental statistical method for estimating the parameters of a statistical model that make the observed data most probable. MLE is grounded in probability theory, providing a strong theoretical basis for parameter estimation. This is becoming more so important to learn fundamentals of MLE concepts as it is at the core of generative modeling (generative AI). Many models used in machine learning and statistics are based on MLE, including logistic regression, survival models, and various types of machine learning algorithms.
MLE is particularly important for data scientists because it underpins many of the probabilistic machine learning models that are used today. These models, which are often used to make predictions or classify data, require an understanding of probability distributions in order to be effective. By learning how to apply MLE, data scientists can better understand how these models work, and how they can be optimized for specific tasks.
In this blog, we will explore the concepts behind MLE and provide examples of how it can be used in practice. We will start with basic concepts of sample space, probability density, parametric modeling and then learn about likelihood and maximum likelihood estimation. We will also learn about how MLE is used in machine learning, before diving into the details of MLE and its applications. Whether you’re a seasoned data scientist or just starting out in the field, this blog will provide valuable insights into one of the key tools used in modern machine learning.
The likelihood function is used to represent the probability of observing the data in sample space assuming the true data generating distribution was the model or density function parametrized by the $\theta$.
Based on the above, we learn that the goal becomes to find the optimal values of parameters of the model or density function, $\theta$ that maximizes the likelihood of seeing or observing the data (X) in the sample space. This technique or method is called as Maximum Likelihood Estimation (MLE). MLE is also used to represent maximum likelihood estimator or maximum likelihood estimate. The goal of the maximum likelihood estimation is to estimate the parameters that maximize the likelihood function. The formula below represents the maximum likelihood estimation function.
Summarizing above, the following are the core concepts that needed to be understood when learning MLE:
When working with neural networks, the loss function is typically minimized. Thus, we can go about finding the set of parameters that minimize the negative log-likelihood such as that given below:
The following are some of the key reasons why you would want to use MLE:
It is recommended to learn some of the following concepts to get a holistic picture of maximum likelihood estimation (MLE) concepts:
MLE underpins numerous statistical and machine learning models, encompassing logistic regression, survival analysis, and a diverse array of machine learning techniques. Let’s understand how MLE applies to logistic regression models.
Recall that logistic regression is used for modeling the probability of a binary outcome based on one or more predictor variables (features). The logistic model predicts the probability that the outcome is 1 (success) as a function of the predictors. It uses the logistic function to ensure the predicted probabilities are between 0 and 1. The logistic function is given by:
$$P(Y=1|X) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_k X_k)}}$$
Where,
The following is how MLE is used in logistic regression:
In summary, MLE is central to logistic regression as it provides a systematic way to estimate the parameters that define the relationship between predictors and the probability of a binary outcome. This methodology ensures that the model is as consistent as possible with the observed data.
Maximum Likelihood Estimation (MLE) is a widely-used statistical method that helps us estimate the parameters of a probability density function which are used to assess the probability of observing the data in the sample space. At its core, maximum likelihood estimation is about finding the values for a set of parameters that provide the highest likelihood for the observed data. Through a variety of examples, we have explored how maximum likelihood estimation can be applied to real-world scenarios, such as predicting consumer behavior, understanding the effectiveness of medical treatments, and more. It is a powerful tool for statisticians, data scientists, and researchers that allows them to make informed decisions based on meaningful data. In short, maximum likelihood estimation is a fundamental concept in statistics that has immense practical applications in various fields, making it an essential technique to be learned and mastered by anyone interested in making data-driven decisions.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
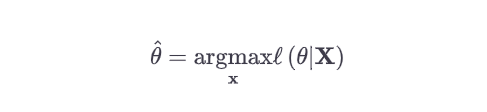{kind=link}
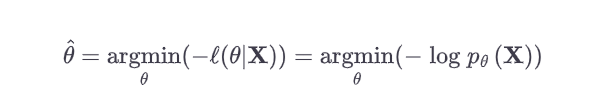{kind=link}
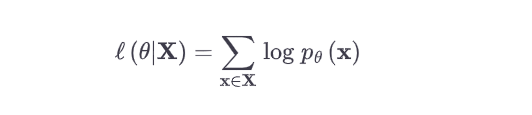{kind=link}