If you’re building machine learning models for solving different prediction problems, you’ve probably heard of clustering. Clustering is a popular unsupervised learning technique used to group data points with similar features into distinct clusters. One of the most widely used clustering algorithms is KMeans, which is popular due to its simplicity and efficiency. However, one major challenge in clustering is determining the optimal number of clusters that should be used to group the data points. This is where the Silhouette Score comes into play, as it helps us measure the quality of clustering and determine the optimal number of clusters. Silhouette score helps us get further clarity for the following questions:
In this post, you will learn about concepts of KMeans Silhouette Score in relation to assessing the quality of K-Means clusters fit on the data. As a data scientist, it is of utmost important to understand the concepts of Silhouette score as it would help in evaluating the quality of clustering done using K-Means algorithm. You may as well want to check some of the following posts in relation to clustering:
The following is an abstract from the paper “Silhouettes: a graphical aid to the interpretation and validation of cluster analysis” that defines the concept of Silhouette.
A new graphical display is proposed for partitioning techniques. Each cluster is represented by a so-called silhouette, which is based on the comparison of its tightness and separation. This silhouette shows which objects lie well within their cluster, and which ones are merely somewhere in between clusters. The entire clustering is displayed by combining the silhouettes into a single plot, allowing an appreciation of the relative quality of the clusters and an overview of the data configuration. The average silhouette width provides an evaluation of clustering validity, and might be used to select an ‘appropriate’ number of clusters.
Peter J. Rousseeuw (1987)
Silhouette score is used to evaluate the quality of clusters created using clustering algorithms such as K-Means in terms of how well samples are clustered with other samples that are similar to each other. The Silhouette score is calculated for each sample of different clusters. In order to calculate the Silhouette score for each observation / data point, the following distances need to be found out for each observations belonging to all the clusters:
Silhouette score, S, for each sample is calculated using the following formula:
[latex]S = \frac{(b – a)}{max(a, b)}[/latex]
The value of Silhouette score varies from -1 to 1. If the score is 1, the cluster is dense and well-separated than other clusters. A value near 0 represents overlapping clusters with samples very close to the decision boundary of the neighbouring clusters. A negative score [-1, 0] indicate that the samples might have got assigned to the wrong clusters.
The Python Sklearn package supports the following different methods for evaluating Silhouette scores.
We will learn about the following in relation to Silhouette score:
Here is the code calculating the silhouette score for K-means clustering model created with N = 3 (three) clusters using Sklearn IRIS dataset.
from sklearn import datasets
from sklearn.cluster import KMeans
#
# Load IRIS dataset
#
iris = datasets.load_iris()
X = iris.data
y = iris.target
#
# Instantiate the KMeans models
#
km = KMeans(n_clusters=3, init='k-means++', max_iter=300, n_init=10, random_state=0)
#
# Fit the KMeans model
#
km.fit_predict(X)
#
# Calculate Silhoutte Score
#
score = silhouette_score(X, km.labels_, metric='euclidean')
#
# Print the score
#
print('Silhouetter Score: %.3f' % score)
Executing the above code predicts the Silhouette score of 0.553. This indicates that the clustering is reasonably good, since the Silhouette Score is closer to 1 than to -1 or 0. A Silhouette Score of 0.553 suggests that the clusters are well separated and that the objects within each cluster are relatively homogeneous.
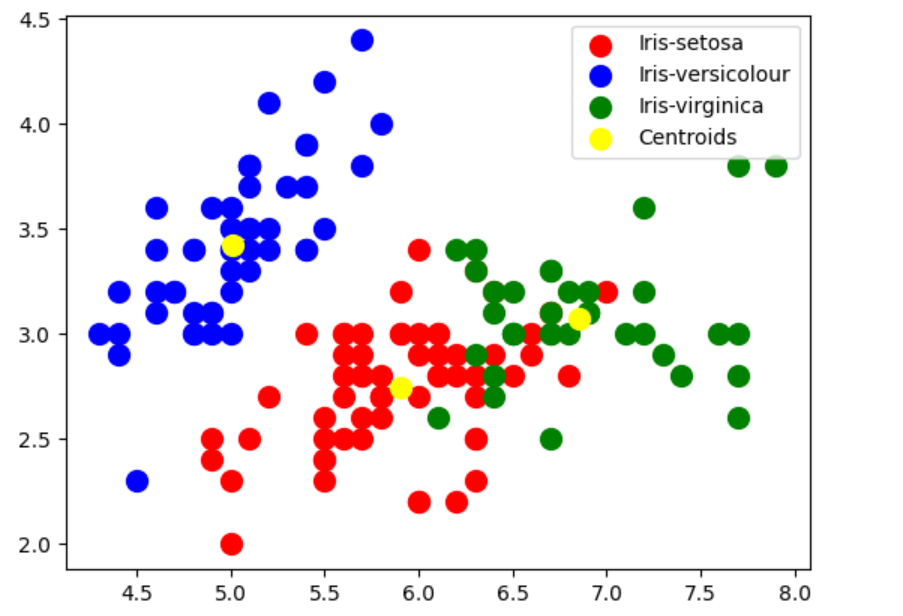
In case you want to visualize the cluster created using above code, here is the python code:
# Visualizing the clusters
#
plt.scatter(X[pred_y == 0, 0], X[pred_y == 0, 1], s = 100, c = 'red', label = 'Iris-setosa')
plt.scatter(X[pred_y == 1, 0], X[pred_y == 1, 1], s = 100, c = 'blue', label = 'Iris-versicolour')
plt.scatter(X[pred_y == 2, 0], X[pred_y == 2, 1], s = 100, c = 'green', label = 'Iris-virginica')
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:,1], s = 100, c = 'yellow', label = 'Centroids')
plt.legend()
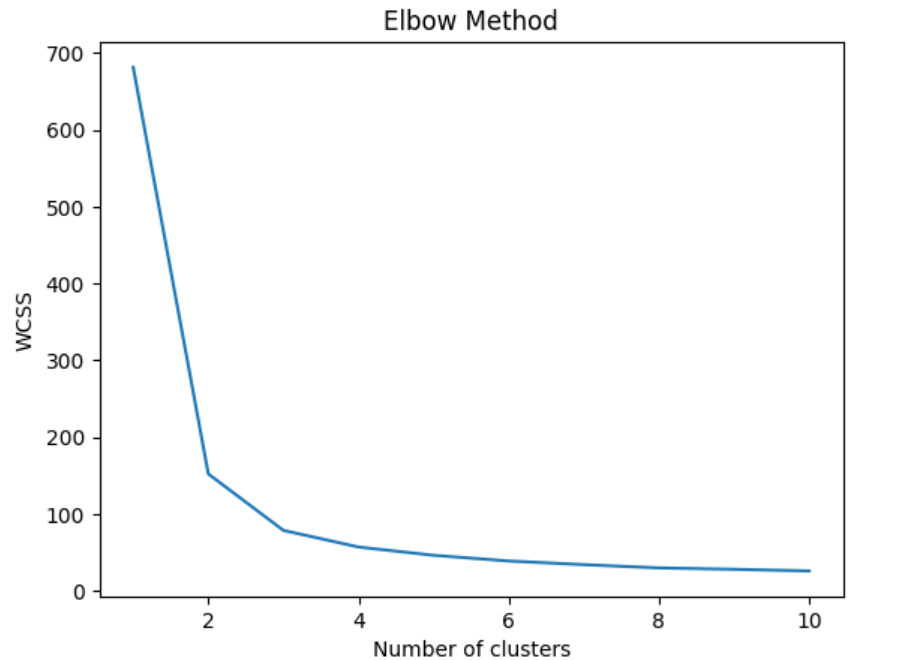
If you have been wondering on how did we arrive at N = 3, we can use the Elbow method to find the optimal number of clusters. Recall that elbow method involves plotting the within-cluster sum of squares (WCSS) against the number of clusters and looking for the “elbow” point in the curve, which represents the point of diminishing returns. In the code given below, firstly the number of clusters is looped from K = 1 to K=10 while fitting KMeans model to the dataset for each value of K. We then calculate the WCSS for each K and plot the results. The resulting plot shows a clear elbow point at K=3, indicating that the optimal number of clusters is 3.
# Finding the optimal number of clusters using Elbow Method
#
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
This is how Elbow plot would look like. The plot shows a clear elbow point at K=3, indicating that the optimal number of clusters is 3.
You can find detailed Python code to draw Silhouette plots for different number of clusters and perform Silhouette analysis appropriately to find the most appropriate cluster. In this section, we will use YellowBrick – a machine learning visualization library to draw the silhouette plots and perform comparative analysis.
Yellowbrick extends the Scikit-Learn API to make model selection and hyperparameter tuning easier. It provides some very useful wrappers to create the visualisation in no time. Here is the code to create Silhouette plot for K-Means clusters with n_cluster as 2, 3, 4, 5.
from yellowbrick.cluster import SilhouetteVisualizer
fig, ax = plt.subplots(2, 2, figsize=(15,8))
for i in [2, 3, 4, 5]:
'''
Create KMeans instance for different number of clusters
'''
km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=100, random_state=42)
q, mod = divmod(i, 2)
'''
Create SilhouetteVisualizer instance with KMeans instance
Fit the visualizer
'''
visualizer = SilhouetteVisualizer(km, colors='yellowbrick', ax=ax[q-1][mod])
visualizer.fit(X)
Executing the above code will result in the following Silhouette plots for 2, 3, 4 and 5 clusters:
Here is the Silhouette analysis done on the above plots with an aim to select an optimal value for n_clusters.
Here is the summary of what you learned in this post in relation to silhouette score concepts:
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}